📝 Paper Summary
LLM Reasoning
Transfer Learning
Mathematical Reasoning
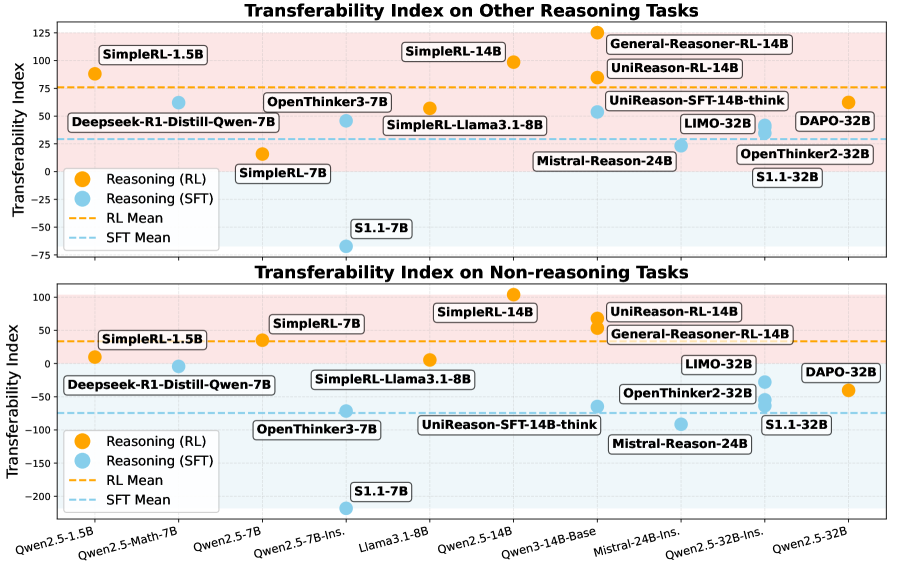
Improvements in math reasoning transfer to general domains only when trained via on-policy reinforcement learning, as supervised fine-tuning causes representation drift and catastrophic forgetting.
Core Problem
Models tuned for math reasoning often achieve high benchmarks scores but fail to transfer these gains to other domains (coding, planning) or suffer catastrophic forgetting on general tasks.
Why it matters:
- Math is used as a proxy for general reasoning, but if gains don't transfer, leaderboards may reflect overfitting rather than true intelligence
- Current post-training recipes rely heavily on SFT on distilled data, which this paper suggests damages general capabilities compared to RL
- Applications require broad competence; a model that solves Olympiad math but cannot follow simple instructions is practically limited
Concrete Example:
A model fine-tuned via SFT on math data might learn to inject reasoning markers like '<<' and '>>' into non-reasoning instruction-following tasks, or lose the ability to answer simple conversational questions, despite scoring high on AIME.
Key Novelty
UniReason: Controlled comparison of SFT vs RL for Transferability
- Demonstrates that the 'fine-tuning paradigm' (RL vs. SFT) is the primary predictor of whether reasoning skills transfer to other domains
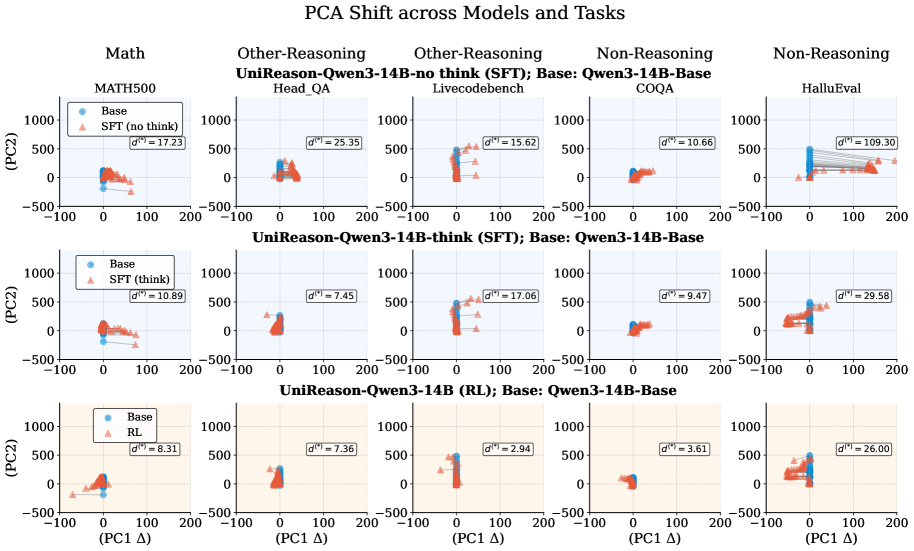
- Uses latent-space PCA and token-space KL divergence analysis to prove SFT distorts internal representations while RL preserves the base model's geometry
Architecture
Conceptual flow of the controlled study (UniReason) comparing SFT and RL paradigms on the same data source
Evaluation Highlights
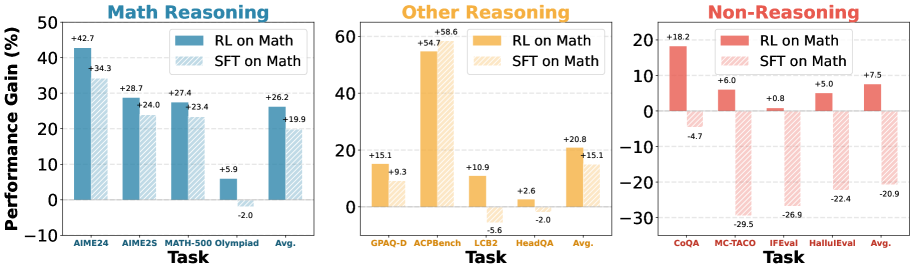
- UniReason-RL achieves 55.7% on AIME24 and 87.8% on MATH500, outperforming SFT counterparts while maintaining general skills
- RL model gains +17.1% accuracy on LiveCodeBench2 compared to the SFT model trained on the exact same data
- RL reduces token distribution shift significantly: 0.019 KL divergence on IFEval vs. 0.283 for SFT
Breakthrough Assessment
9/10
Provides a crucial pivot for the field by empirically proving RL's superiority over SFT for generalizable reasoning, backed by rigorous latent space analysis and controlled experiments.