📝 Paper Summary
Vision-Language-Action (VLA) Models
Robotic Manipulation
Embodied Reasoning
OneTwoVLA integrates high-level reasoning and low-level control into a single model that autonomously decides when to reason and when to act, enabling efficient execution and error recovery.
Core Problem
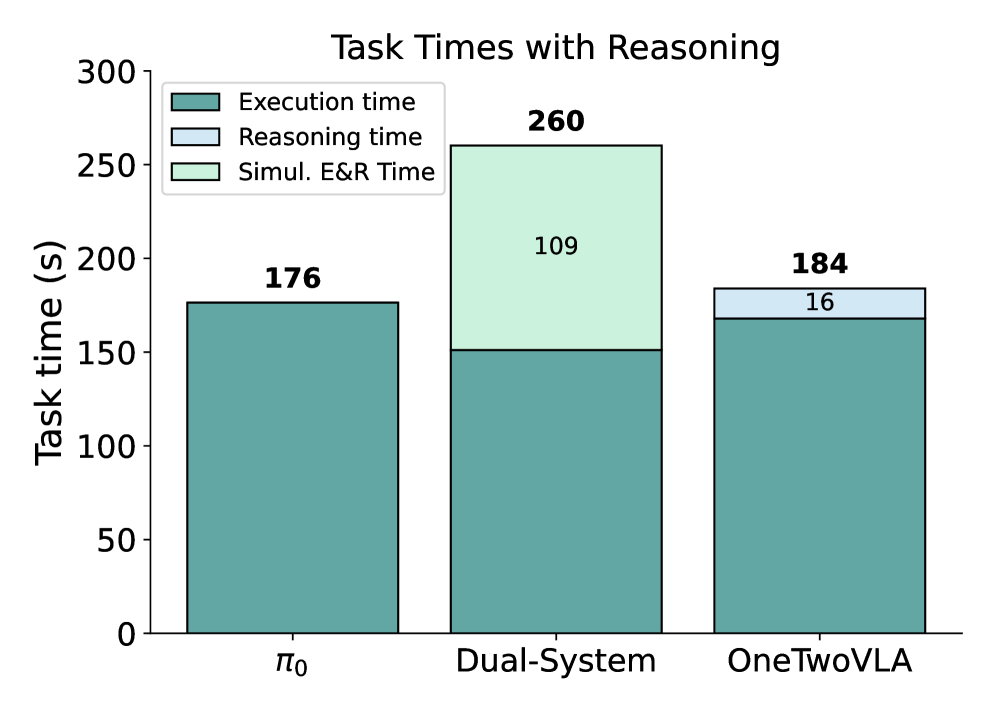
Dual-system approaches separate high-level planners (System 2) from low-level actors (System 1), leading to capability mismatches where planners command infeasible actions and latency issues that hinder real-time responsiveness.
Why it matters:
- Lack of mutual awareness between separated systems causes execution failures when the planner generates instructions the actor cannot physically perform.
- Significant inference latency in large reasoning models prevents robots from reacting quickly to dynamic changes or errors during execution.
Concrete Example:
In a 'Tomato-Egg' cooking task, a dual-system planner might instruct the robot to 'add green onion' because it is in the recipe, failing to realize no green onion is visible; the separated actor then stalls or behaves erratically.
Key Novelty
Adaptive Reasoning via Unified VLA
- The model uses special tokens ([BOR] for reasoning, [BOA] for acting) to autonomously switch modes, reasoning only at critical moments (e.g., error detection) while acting efficiently otherwise.
- Utilizes a scalable pipeline to synthesize 'reasoning-centric' vision-language data (using FLUX.1 and Gemini) which is co-trained with robot data to boost generalization.
Architecture
Inference flow of OneTwoVLA. The model takes visual and text inputs, first predicting a decision token ([BOR] or [BOA]).
Evaluation Highlights
- +30% success rate improvement over the flat VLA baseline (pi_0) across three long-horizon manipulation tasks (Tomato-Egg, Hotpot, Cocktail).
- +24% success rate improvement over a dual-system baseline (Gemini 2.5 Pro + pi_0) on the same long-horizon tasks.
- Demonstrates zero-shot generalization to novel instructions (e.g., 'Help me stay awake' -> make coffee) by co-training with 16,000 synthetic vision-language samples.
Breakthrough Assessment
8/10
Successfully unifies System 1 and System 2 in robotics with a practical adaptive mechanism, showing significant gains over strong baselines and demonstrating how synthetic data can bridge the reasoning gap.
