📝 Paper Summary
LLM Reasoning
Reinforcement Learning (RL) Scaling
Inference Scaling
T1 scales reinforcement learning for reasoning by initializing with trial-and-error CoT data, oversampling with high temperature during training, and demonstrating that longer single-generation thinking directly improves performance.
Core Problem
Current reasoning approaches rely on imitation learning or repeated sampling with verifiers, which fail to fundamentally improve the policy model's ability to self-explore or scale performance with longer thinking.
Why it matters:
- Repeated sampling relies on external verifiers and does not improve the core model's reasoning capabilities.
- Existing RL attempts yield modest improvements in complex reasoning compared to imitation learning stages.
- True inference scaling requires models to 'think longer' effectively rather than just selecting from many short attempts.
Concrete Example:
A standard SFT model might output a correct answer through a memorized shortcut. However, when faced with a complex math problem, it fails to self-correct if the first step is wrong. T1 explicitly learns to say 'Wait, perhaps...' or 'Let's try a different approach', recovering from errors within a single long generation.
Key Novelty
Scaled RL with Exploration and Long-Thinking Inference
- Initializes the policy with synthetic CoT data that explicitly includes reflection, trial-and-error, and self-verification, rather than just perfect reasoning paths.
- Scales RL training by oversampling (K=64) with high temperature to force exploration, stabilized by penalties for repetition and garbage text.
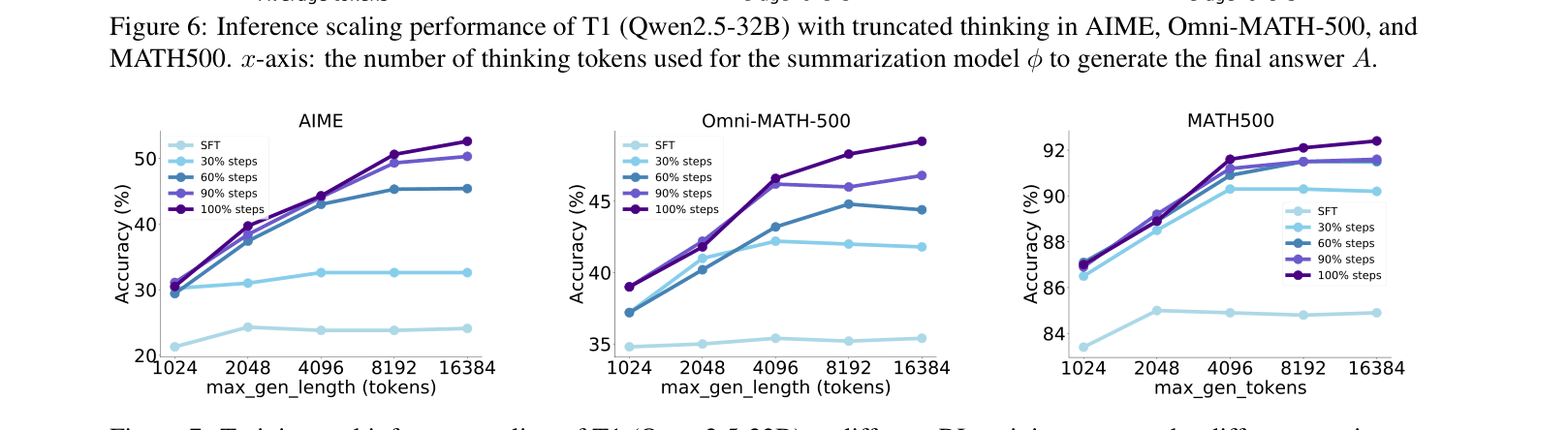
- Analyzes inference scaling by truncating single long reasoning chains, showing that increased token budgets directly correlate with accuracy without external verifiers.
Architecture
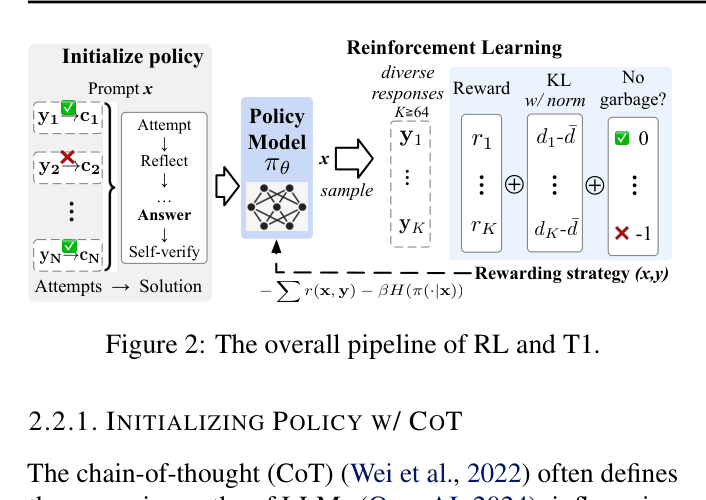
The overall T1 training pipeline: SFT initialization with CoT data (Attempt/Reflect/Answer), followed by scaled RL training.
Evaluation Highlights
- Outperforms QwQ-32B-Preview on MATH500 (92.4% vs 90.6%) and AIME 2024 (50.6% vs 50.0%) using Qwen2.5-32B base.
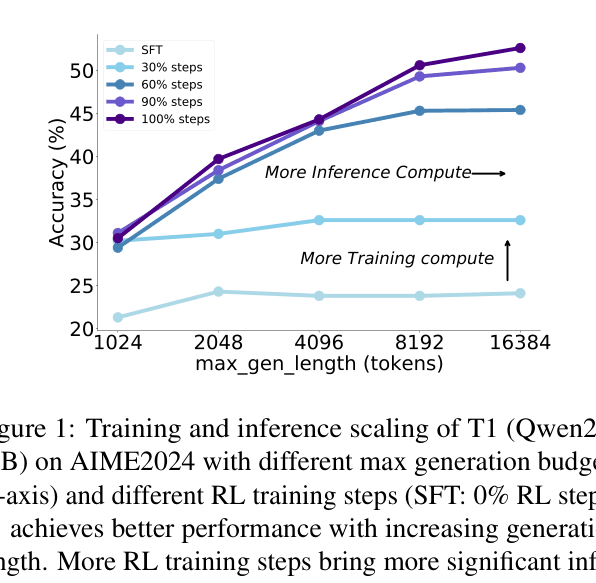
- Achieves +25.7% accuracy gain on AIME (24.9% → 50.6%) via RL scaling compared to its own SFT baseline.
- Demonstrates inference scaling: Extending reasoning length consistently improves AIME accuracy from ~24% to 50% as thinking tokens increase from 2k to 6k.
Breakthrough Assessment
9/10
Significantly advances open-source reasoning by replicating o1-like inference scaling behaviors using standard RL techniques (not proprietary algorithms) and open weights.