📝 Paper Summary
Speculative Decoding
Efficient LLM Inference
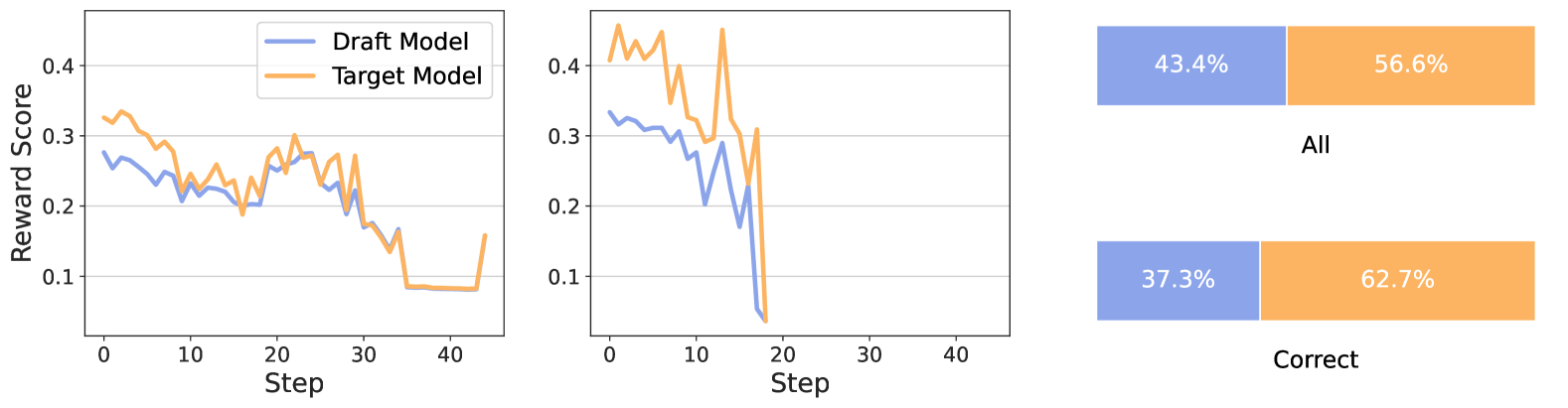
RSD accelerates LLM reasoning by accepting draft steps that have high reward scores, allowing a controlled bias towards correct answers even if they don't match the target model's exact distribution.
Core Problem
Standard speculative decoding strictly enforces unbiasedness, rejecting valid draft tokens if they don't match the target model's distribution, which wastes computation in complex reasoning tasks where diverse correct paths exist.
Why it matters:
- Strict unbiasedness forces the rejection of high-quality draft outputs simply because they differ from the target model's preference, negating efficiency gains.
- Long-horizon reasoning tasks (like math or coding) generate many tokens, making inference costs prohibitively high without efficient acceleration.
- Existing parallel decoding methods struggle to balance the trade-off between speed and the rigorous accuracy required for multi-step reasoning.
Concrete Example:
In a math problem, a small draft model might generate a valid correct step that the large model didn't prioritize (low probability). Standard speculative decoding would reject this valid step to maintain distribution matching, forcing a costly regeneration. RSD detects the step is 'correct' via a reward model and accepts it, saving compute.
Key Novelty
Reward-Guided Speculative Decoding (RSD)
- Replaces the strict probability-matching acceptance criterion of standard speculative decoding with a reward-based criterion.
- Uses a process reward model to evaluate draft steps; if a step's reward is above a dynamic threshold, it is accepted regardless of the target model's probability distribution.
- Constructs a theoretical mixture distribution that shifts weight between the cheap draft model (for high-reward steps) and the expensive target model (for low-reward steps).
Architecture
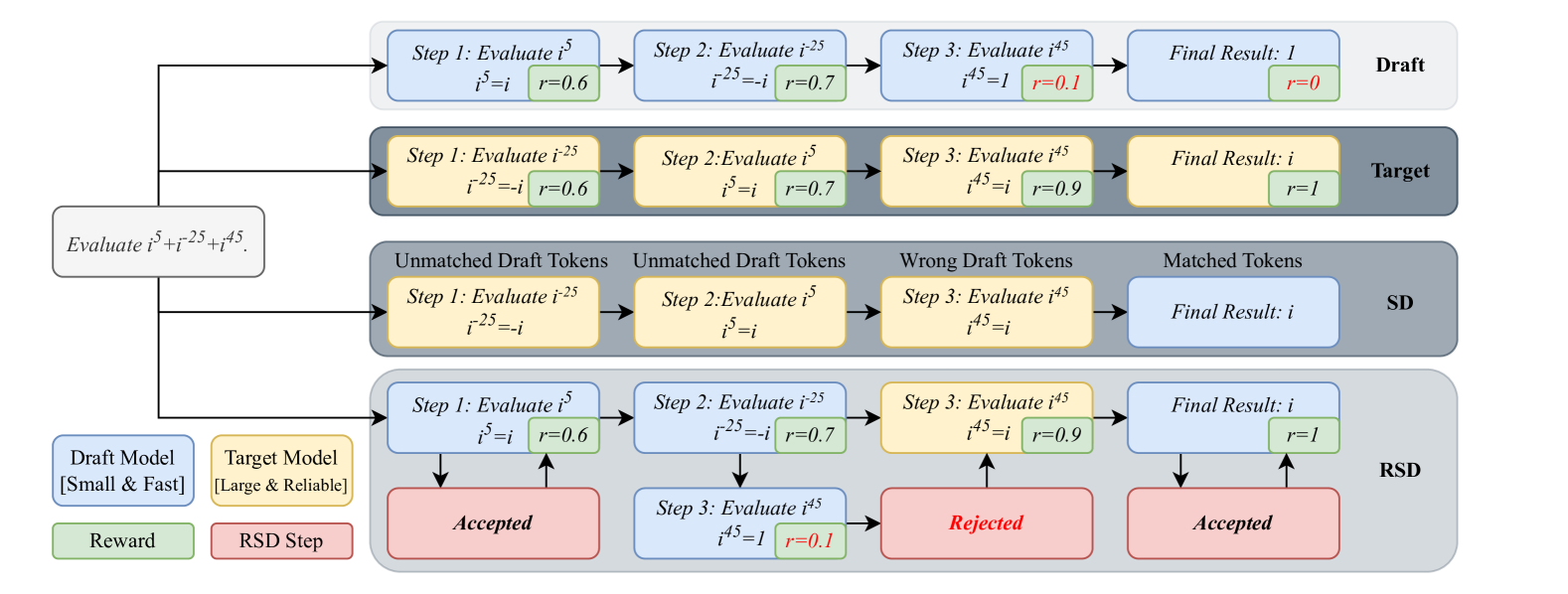
Overview of the Reward-Guided Speculative Decoding framework. It illustrates the timeline of generating steps: the draft model proposes a step, a reward model evaluates it, and depending on the score, it is either accepted (green path) or rejected and regenerated by the target model (red path).
Evaluation Highlights
- Achieves up to 4.4× fewer FLOPs compared to decoding with the target model alone on reasoning benchmarks.
- Improves reasoning accuracy by up to +3.5 points on average compared to standard speculative decoding (SD) while being more efficient.
- Outperforms standard decoding on hard tasks: +1.6% accuracy on MATH500 using Llama-3-8B-Instruct as draft and Llama-3-70B-Instruct as target.
Breakthrough Assessment
8/10
Significantly relaxes the 'unbiased' constraint of speculative decoding in a theoretically grounded way, unlocking speedups for reasoning tasks where strict distribution matching is less important than correctness.