📝 Paper Summary
Text-to-Image Generation
Instruction-based Image Editing
Chain-of-Thought Reasoning
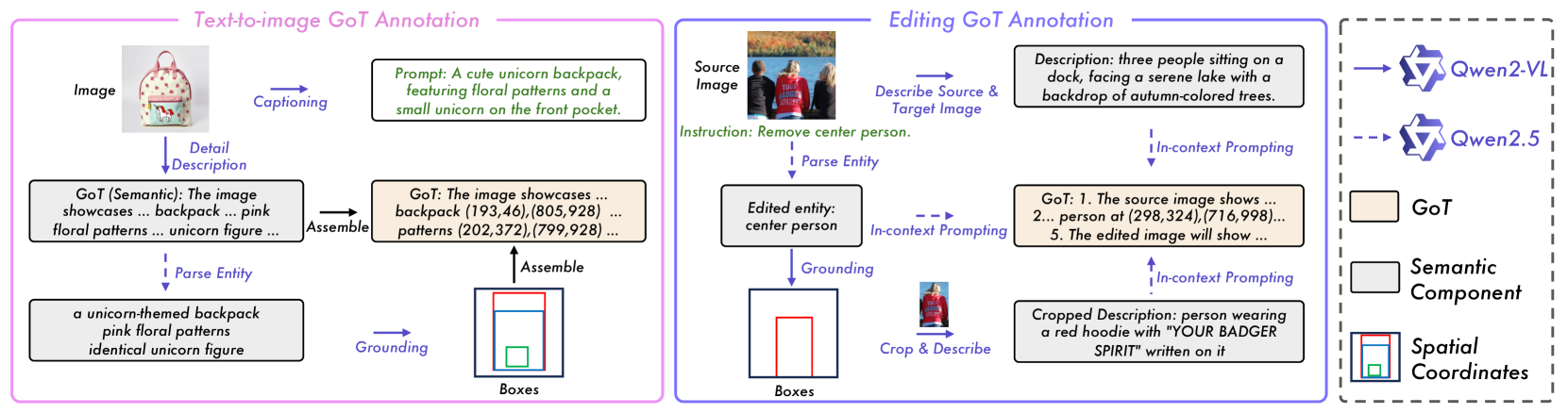
GoT introduces a paradigm where an MLLM first generates a semantic-spatial reasoning chain explaining the scene layout, which then guides a diffusion model via a specialized guidance module to produce images.
Core Problem
Current diffusion models map text directly to pixels without explicit reasoning, struggling with complex scenes requiring precise spatial arrangements and object interactions that humans naturally plan.
Why it matters:
- Existing methods treat text prompts as static representations, failing to capture the step-by-step logic required for complex compositions
- There is a disconnect between the advanced reasoning capabilities of MLLMs and the lack of reasoning in visual generation systems
- Previous layout-based methods treat planning and generation as separate stages rather than an integrated end-to-end reasoning process
Concrete Example:
When tasked to 'replace the giant leaf with an umbrella', standard models might just swap pixels based on keywords. GoT first reasons: 'analyze scene -> plan edit at specific coordinates -> describe final state', ensuring the umbrella is correctly grounded and the scene remains coherent.
Key Novelty
Generation Chain-of-Thought (GoT)
- Shifts visual generation from direct mapping to a reasoning-guided process where the model outputs a natural language plan with spatial coordinates before generating pixels
- Uses a novel Semantic-Spatial Guidance Module (SSGM) to inject the MLLM's reasoning chain directly into the diffusion process via semantic embeddings and spatial masks
- Unifies generation and editing in one framework by treating editing as a reasoning task involving reference image analysis and modification planning
Architecture
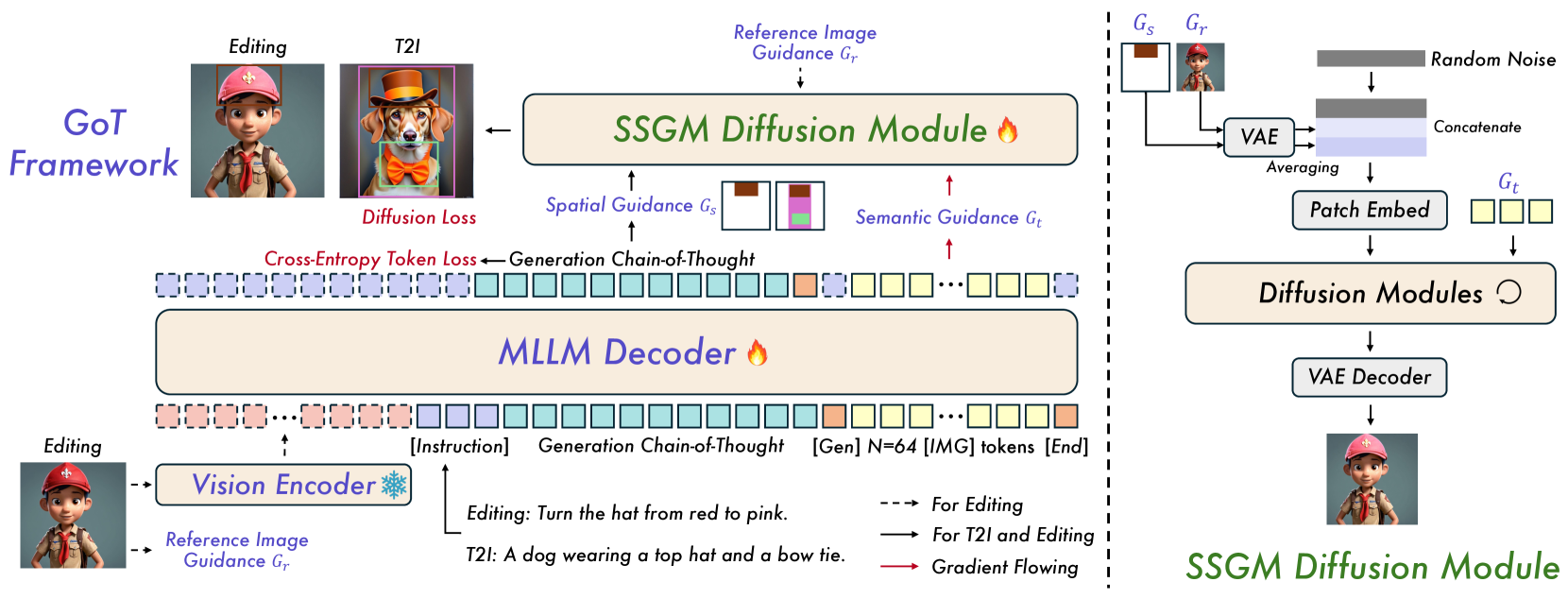
The overall GoT framework architecture, illustrating the flow from input prompt to MLLM reasoning, to the Semantic-Spatial Guidance Module, and finally to the Diffusion Model.
Breakthrough Assessment
8/10
Proposes a significant architectural shift by integrating explicit MLLM reasoning chains into the diffusion loop end-to-end, supported by a massive new dataset (9M+ samples).