📝 Paper Summary
Robotic Manipulation
Vision-Language-Action (VLA) Models
Embodied AI
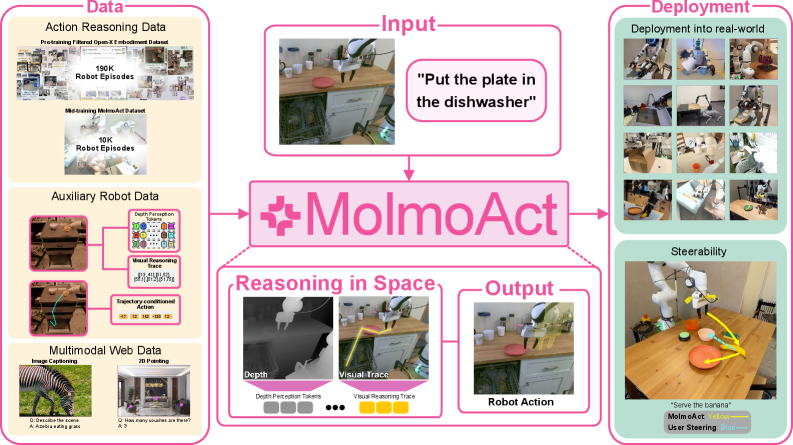
MolmoAct improves robotic control by inserting intermediate spatial reasoning steps—specifically depth perception tokens and visual trajectory traces—between observation and action, rather than mapping pixels directly to control.
Core Problem
Current Vision-Language-Action (VLA) models map perception directly to control, lacking explicit spatial reasoning and depth understanding, which limits their adaptability, generalization, and explainability.
Why it matters:
- Direct mapping models (VLAs) are brittle and struggle to transfer across tasks or scenes because they lack grounded 3D understanding
- Robots need to reason about constraints and goals ('think before acting') to be adaptable, similar to how LLMs benefit from Chain-of-Thought
- Language-only steering is often ambiguous; users need precise ways to guide robot behavior that standard VLAs do not support
Concrete Example:
When a user wants a robot to move an object along a specific path, language commands like 'move left' are ambiguous regarding magnitude and trajectory. Current VLAs cannot easily accept visual corrections. MolmoAct allows users to draw a 'visual reasoning trace' directly on the image to steer the action.
Key Novelty
Action Reasoning Model (ARM) with Spatial Chain-of-Thought
- Instead of reasoning in language, the model reasons in space by autoregressively generating depth perception tokens to understand 3D geometry
- It then generates a 'visual reasoning trace' (a 2D polyline on the image) representing the planned end-effector path before predicting low-level actions
- Uses a novel action tokenization scheme that maps continuous action bins to byte-level BPE symbols, preserving ordinal locality for better training stability
Architecture
The three-stage inference pipeline: Perception -> Planning -> Action.
Evaluation Highlights
- Achieves 70.5% zero-shot accuracy on SimplerEnv Visual Matching tasks, surpassing closed-source baselines like pi0 and GR00T N1.5
- Outperforms ThinkAct by +6.3% on long-horizon tasks within the LIBERO benchmark (86.6% average success)
- Improves real-world task progression by +22.7% on bimanual tasks compared to pi0-FAST via fine-tuning
Breakthrough Assessment
8/10
Strong empirical gains over major baselines (pi0, GR00T) and a distinct architectural shift from direct VLA mapping to spatial reasoning/planning. The release of a mid-training dataset is also significant.