📝 Paper Summary
Code Generation
Reasoning Models
Reinforcement Learning
Scaling general-purpose reinforcement learning allows the o3 model to achieve gold-medal competitive programming performance by internally learning verification strategies, surpassing specialized systems that rely on hand-crafted heuristics.
Core Problem
Solving complex algorithmic problems requires rigorous reasoning and correctness verification, which standard language models fail at. Previous state-of-the-art systems relied on brittle, hand-engineered selection pipelines rather than intrinsic model capability.
Why it matters:
- Hand-crafted heuristics (like clustering thousands of samples) are domain-specific and do not scale to general reasoning tasks
- Competitive programming serves as a rigorous, objectively gradable benchmark for measuring deep reasoning capabilities in AI
- Reliable code generation requires models to verify their own outputs, a capability lacking in standard LLMs which often hallucinate plausibly-looking but incorrect code
Concrete Example:
In IOI 2024, the specialized o1-ioi system required generating 10,000 solutions and using external hand-coded clustering to select the best one, scoring only 213 points. In contrast, o3 autonomously wrote a brute-force 'slow' solution to verify its own optimized solution, achieving 395 points without external heuristics.
Key Novelty
Emergent Test-Time Verification via General-Purpose RL
- Replacing hand-engineered selection pipelines (clustering, reranking) with intrinsic chain-of-thought reasoning trained via reinforcement learning
- The model learns to 'double-check' its work by writing alternate implementations (e.g., brute force) to test against its primary solution during inference
Architecture
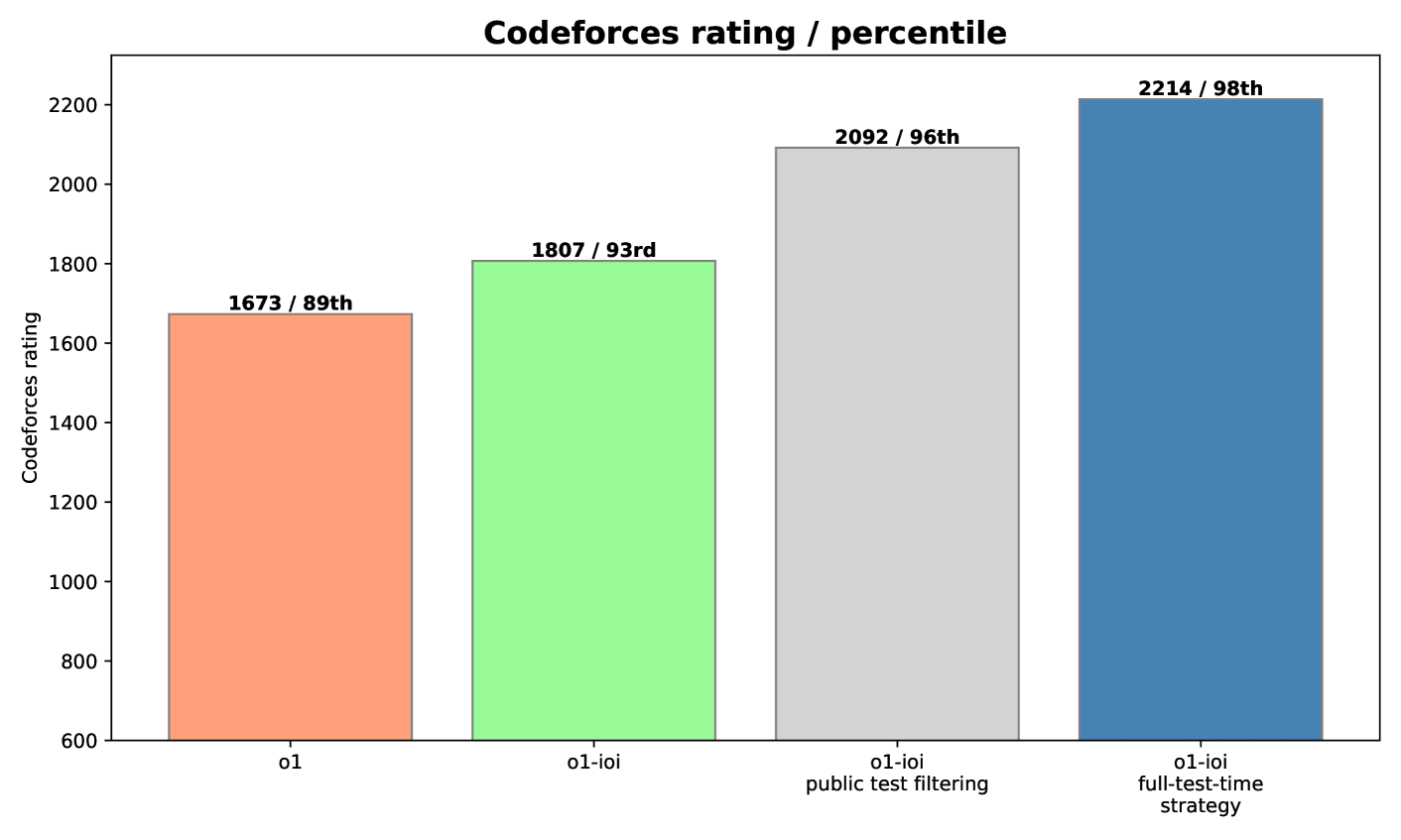
The o1-ioi specialized inference pipeline designed to mimic human competitive programming strategies.
Evaluation Highlights
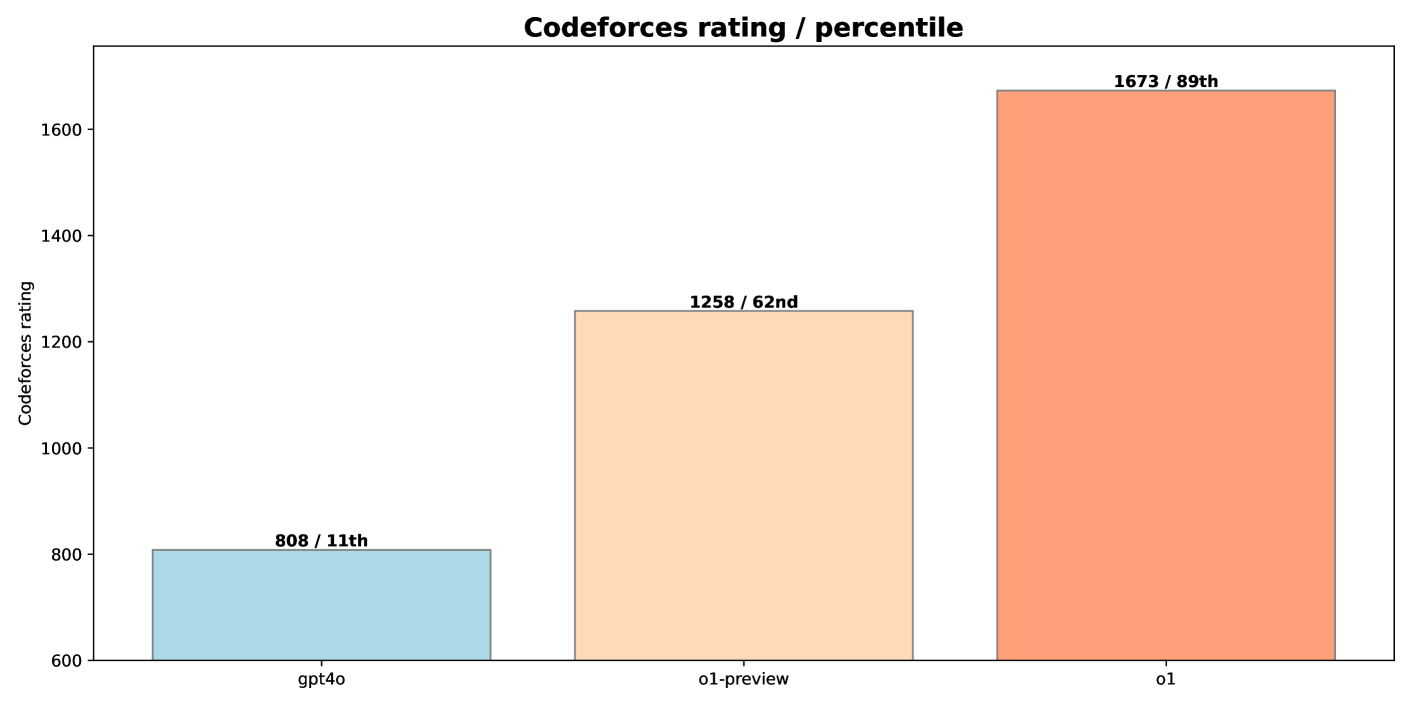
- o3 achieved a CodeForces rating of 2724 (99.8th percentile), comparable to elite human competitors
- o3 scored 395.64 points in the 2024 International Olympiad in Informatics (IOI) under strict constraints, surpassing the Gold Medal threshold of ~360
- o1-ioi (specialized system) achieved 98th percentile on CodeForces (rating 2214) using complex test-time strategies
Breakthrough Assessment
9/10
o3 represents a massive leap, achieving Gold Medal status in one of the hardest human cognitive benchmarks (IOI) purely through RL scaling, rendering complex domain-specific engineering obsolete.