📝 Paper Summary
Mathematical Reasoning
Synthetic Data Generation
Tool-Integrated Reasoning
OpenMath-Nemotron achieves state-of-the-art math reasoning by training on a massive synthetic dataset of tool-integrated solutions and employing a generative model to select the best answer from multiple candidates.
Core Problem
Strong open-weight reasoning models like DeepSeek-R1 struggle to integrate code execution (Tool-Integrated Reasoning) via prompting alone, and standard majority voting fails to bridge the gap between pass@1 and theoretical pass@k performance.
Why it matters:
- Pure text reasoning often fails on complex calculations where code is reliable, but models trained only on text reasoning resist using tools even when instructed
- Majority voting requires generating many expensive solutions and treats them independently, ignoring the model's ability to critically evaluate and compare reasoning traces
- Existing competition-level math benchmarks (AIMO) have strict time limits, requiring efficient inference strategies rather than massive brute-force sampling
Concrete Example:
When prompted to use Python, models like DeepSeek-R1 often refuse or write code only to verify trivial arithmetic. In contrast, the proposed TIR model autonomously writes code to perform exhaustive searches or use numeric solvers for problems where analytical solutions are infeasible.
Key Novelty
OpenMath-Nemotron & GenSelect
- Created OpenMathReasoning: a massive dataset of 540K problems with 3.2M Chain-of-Thought and 1.7M Tool-Integrated Reasoning solutions generated via iterative rejection sampling
- Developed an iterative 'training-generation-filtering' loop to force instruction-following models to produce high-quality code-integrated reasoning, which is then used to train base reasoning models
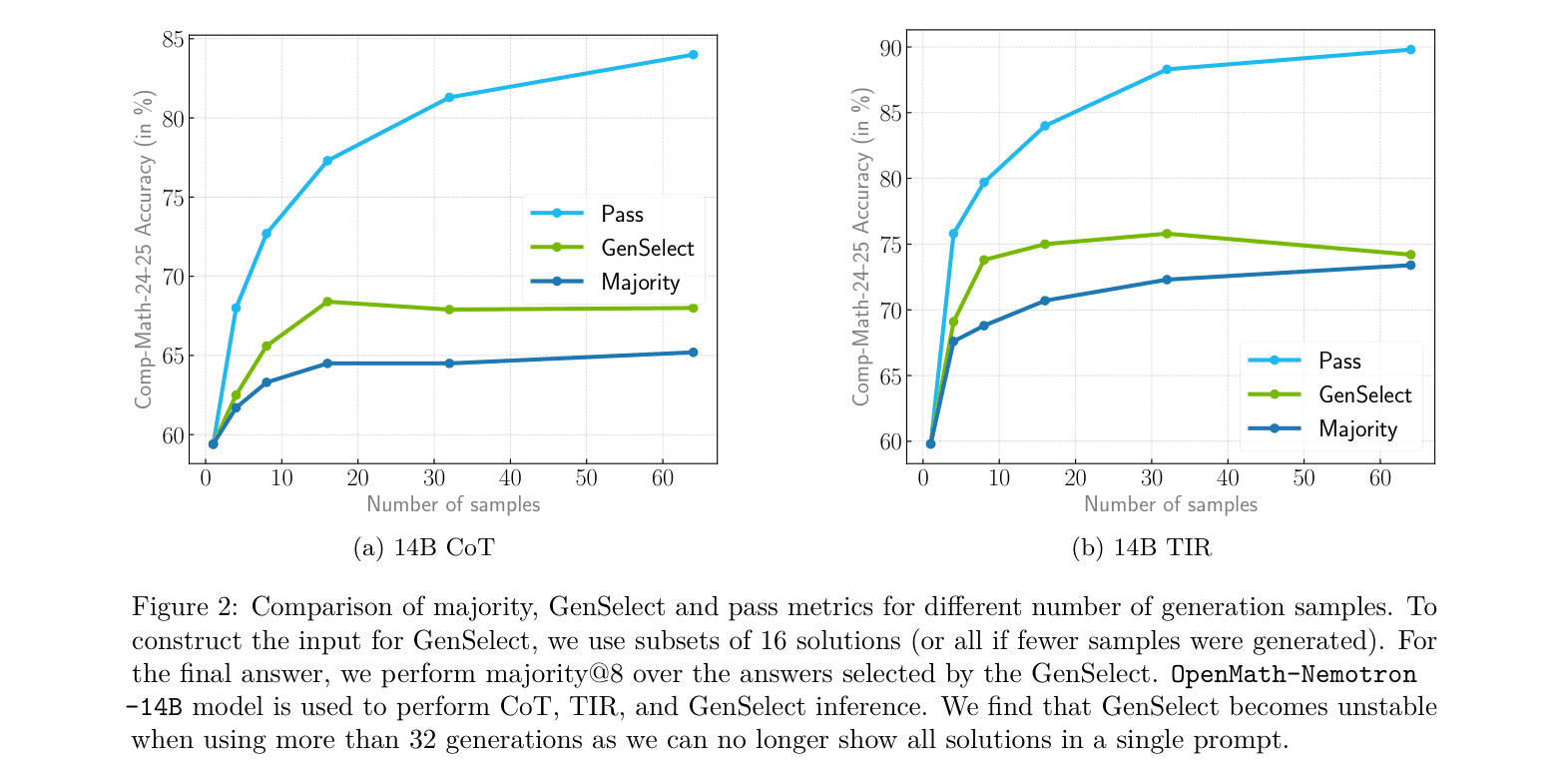
- Generative Solution Selection (GenSelect): Instead of a scalar score, a model is trained to read multiple candidate summaries and generate a reasoning trace concluding with the best solution
Architecture
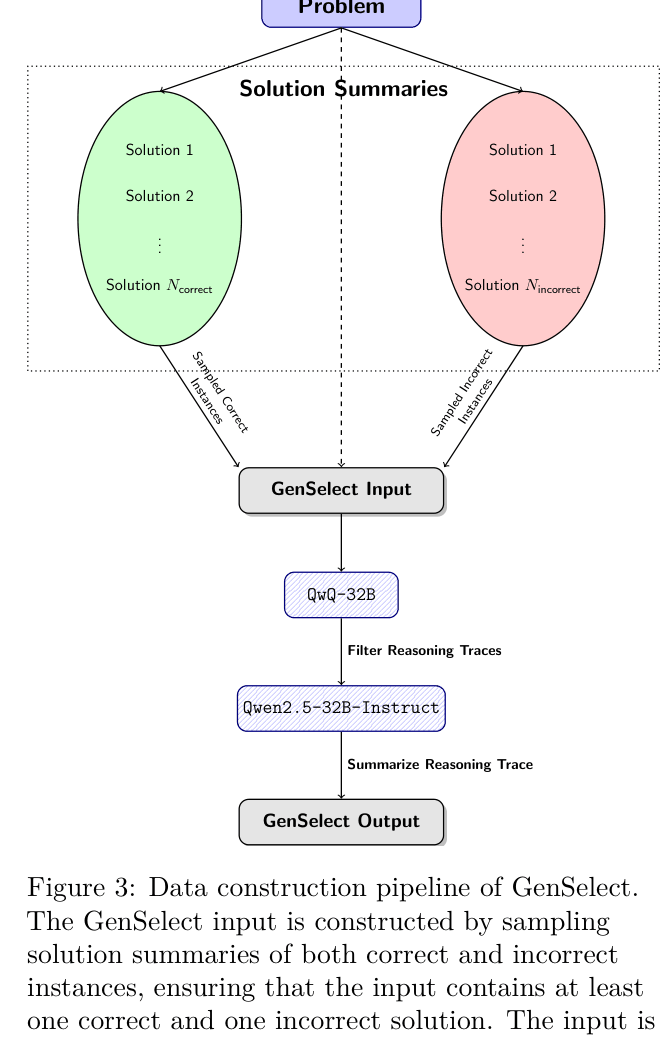
The Data Construction Pipeline for GenSelect (Generative Solution Selection).
Evaluation Highlights
- OpenMath-Nemotron-32B (TIR + Self GenSelect) achieves 93.3% accuracy on the Comp-Math-24-25 benchmark, significantly outperforming DeepSeek-R1 (79.1%)
- Winning submission for AIMO-2 Kaggle competition, solving 34/50 private test problems (1st place)
- OpenMath-Nemotron-7B with GenSelect (86.7%) outperforms the much larger DeepSeek-R1 (79.1%) on the Comp-Math-24-25 benchmark
Breakthrough Assessment
9/10
Establishes a new SOTA for open-weight math models, releases a massive high-quality dataset (OpenMathReasoning), and demonstrates a viable recipe for fusing code execution with reasoning models.