📝 Paper Summary
Language Model Scaling Laws
Parameter Efficient Reasoning
Looped transformers, which iteratively reuse a small block of layers, achieve strong reasoning performance by increasing effective depth without increasing parameter count, acting as an implicit chain-of-thought mechanism.
Core Problem
Standard scaling laws suggest performance depends primarily on parameter count, but reasoning problems (like math or induction) often require computational depth (number of steps) rather than just memory capacity.
Why it matters:
- Building deeper models to handle complex reasoning usually requires a linear increase in parameters and memory, which is computationally expensive
- Current non-looped models may fail at reasoning tasks even with many parameters if they lack sufficient depth to process compositional steps
Concrete Example:
In an n-ary addition task (e.g., adding 32 numbers), a shallow model with many parameters fails to track the carry-over operations, whereas a looped model with few parameters but high effective depth can solve it.
Key Novelty
Reasoning via Looped Transformers ($k \otimes L$)
- Decouple model depth from parameter count by iteratively applying the same block of $k$ Transformer layers $L$ times (weight tying)
- Theoretically framing the 'loop' as generating 'latent thoughts', allowing the model to simulate Chain-of-Thought (CoT) reasoning steps internally without outputting tokens
Architecture
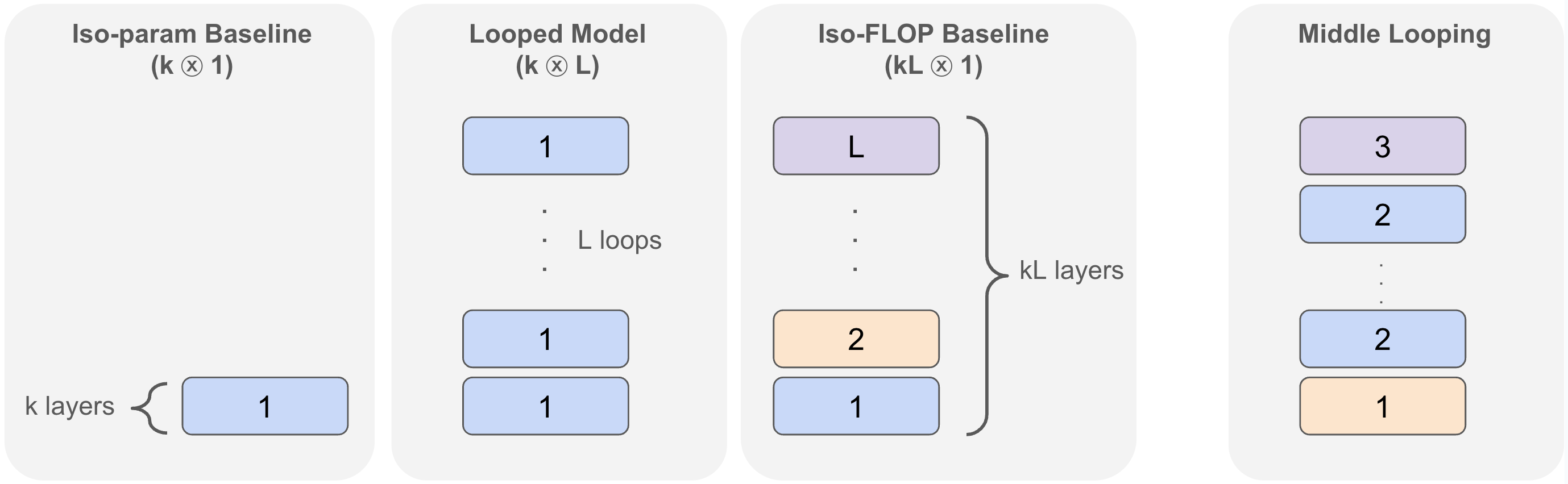
Conceptual illustration of looped vs. non-looped models (described in text)
Evaluation Highlights
- On 32-operand addition, a looped model ($k \otimes 12/k$) nearly matches the performance of a full 12-layer non-looped baseline while using significantly fewer parameters ($1/L$ fraction).
- On i-GSM (synthetic math), looped models match or outperform iso-flop non-looped models (same effective depth, more params) and significantly outperform iso-param models.
- In 1B-scale language modeling, looped models demonstrate an inductive bias for reasoning, achieving competitive performance on math/coding tasks compared to iso-flop baselines despite having worse perplexity.
Breakthrough Assessment
8/10
Challenges the dominant parameter-scaling paradigm by demonstrating that depth via looping is sufficient for reasoning, offering a pathway to highly parameter-efficient 'thinking' models.