📝 Paper Summary
Reinforcement Learning with Verifiable Rewards (RLVR)
LLM Reasoning
Inference Scaling
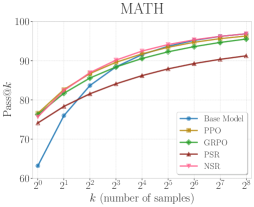
Decomposing RLVR reveals that solely penalizing incorrect reasoning paths (NSR) improves inference scaling and diversity more effectively than reinforcing correct ones, which tends to collapse the solution space.
Core Problem
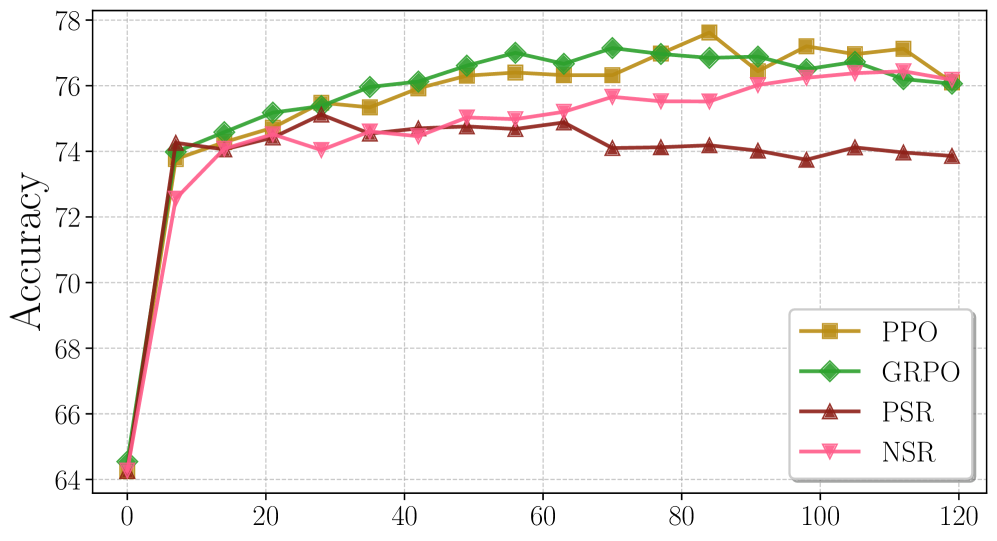
Standard RLVR blends signals from correct and incorrect responses, but the specific mechanisms driving performance are unclear; reinforcing correct answers often leads to mode collapse, hurting performance at higher compute budgets (Pass@k).
Why it matters:
- Models trained with standard RL (PPO/GRPO) often lose performance advantages at large sampling budgets (high k) due to reduced diversity
- Understanding whether learning comes from 'knowing what is right' vs 'knowing what is wrong' is critical for designing better reasoning objectives
- Solely reinforcing correct paths (Positive Sample Reinforcement) creates overconfident models that fail to explore valid alternative reasoning strategies
Concrete Example:
When a model is trained only on correct samples (PSR), it might learn to memorize one specific solution path for a math problem. During testing, if allowed 256 attempts, it mostly repeats that single path. If that path is wrong for a slight variation, the model fails. In contrast, a model trained to avoid errors (NSR) suppresses known bad paths but keeps the rest of its distribution open, finding the correct answer through diverse valid attempts.
Key Novelty
Decomposition of RLVR into Positive (PSR) and Negative Sample Reinforcement (NSR)
- Decomposes the RLVR objective into two separate components: maximizing likelihood of correct responses (PSR) and minimizing likelihood of incorrect responses (NSR)
- Demonstrates that NSR alone—learning only from mistakes—is sufficient to match or beat full PPO/GRPO baselines on inference scaling metrics
- Shows via gradient analysis that NSR works by 'pruning' incorrect paths while redistributing probability mass to other plausible priors, preserving diversity unlike PSR
Architecture
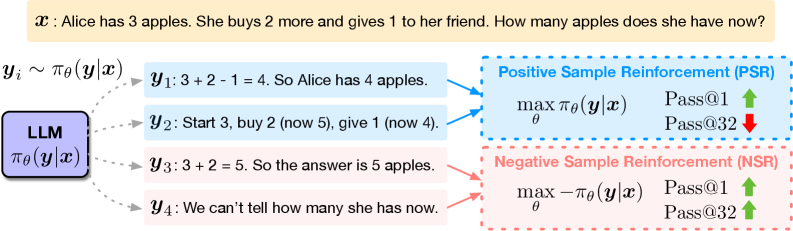
Decomposition of RLVR into Positive Sample Reinforcement (PSR) and Negative Sample Reinforcement (NSR) learning paradigms.
Evaluation Highlights
- NSR matches thinking-mode performance on MATH using a non-thinking base model: 94.0 Pass@1 vs 94.5 (Target) and 98.0 Pass@64 vs 97.8 (Target)
- NSR consistently outperforms Positive Sample Reinforcement (PSR) on Pass@k for k > 8, avoiding the diversity collapse observed in PSR
- Proposed Weighted-REINFORCE (upweighting NSR) consistently improves over strong baselines like PPO and GRPO on MATH, AIME 2025, and AMC23
Breakthrough Assessment
8/10
Provides a fundamental insight into *why* RLVR works (negative signal is more critical for scaling than positive signal) and offers a simpler, more effective training paradigm.