📝 Paper Summary
Visual Reasoning
Vision-Language Models (VLMs)
Reinforcement Fine-Tuning (RFT)
ThinkLite-VL achieves state-of-the-art visual reasoning by selecting a small subset of high-difficulty training samples using MCTS iteration counts as a proxy for hardness, then applying reinforcement fine-tuning without distillation.
Core Problem
Current VLM reasoning improvements rely on cumbersome pipelines involving knowledge distillation and large datasets, often failing to leverage self-improvement effectively due to poor sample selection.
Why it matters:
- Distillation pipelines are computationally expensive and limit models to the teacher's capacity.
- Existing RFT methods for VLMs struggle because they train on samples that are either too easy (trivial) or too hard (unsolvable), leading to inefficient learning.
- Reliably quantifying 'sample difficulty' for multimodal tasks remains non-trivial and unaddressed in scalable ways.
Concrete Example:
A VLM might easily solve a simple chart question but fail repeatedly on a complex geometry proof. Training on the easy chart wastes compute, while training on the geometry proof without intermediate feedback fails. ThinkLite-VL identifies the geometry proof as 'challenging but solvable' (high MCTS iterations) and prioritizes it for RFT.
Key Novelty
ThinkLite-VL (MCTS-Guided Sample Selection for RFT)
- Repurposes Monte Carlo Tree Search (MCTS) from an inference tool to a training data filter, using the number of reasoning iterations required to solve a problem as a 'difficulty score'.
- Demonstrates that Reinforcement Fine-Tuning (RFT) on a small, curated subset of 'appropriately challenging' samples (high iteration count) is far more effective than training on larger, random datasets.
- Eliminates the need for Supervised Fine-Tuning (SFT) or knowledge distillation, achieving self-improvement purely through difficulty-aware RFT.
Architecture
Conceptual pipeline: Data Pool -> MCTS Difficulty Evaluation -> Filtered High-Difficulty Subset -> RFT Training -> ThinkLite-VL.
Evaluation Highlights
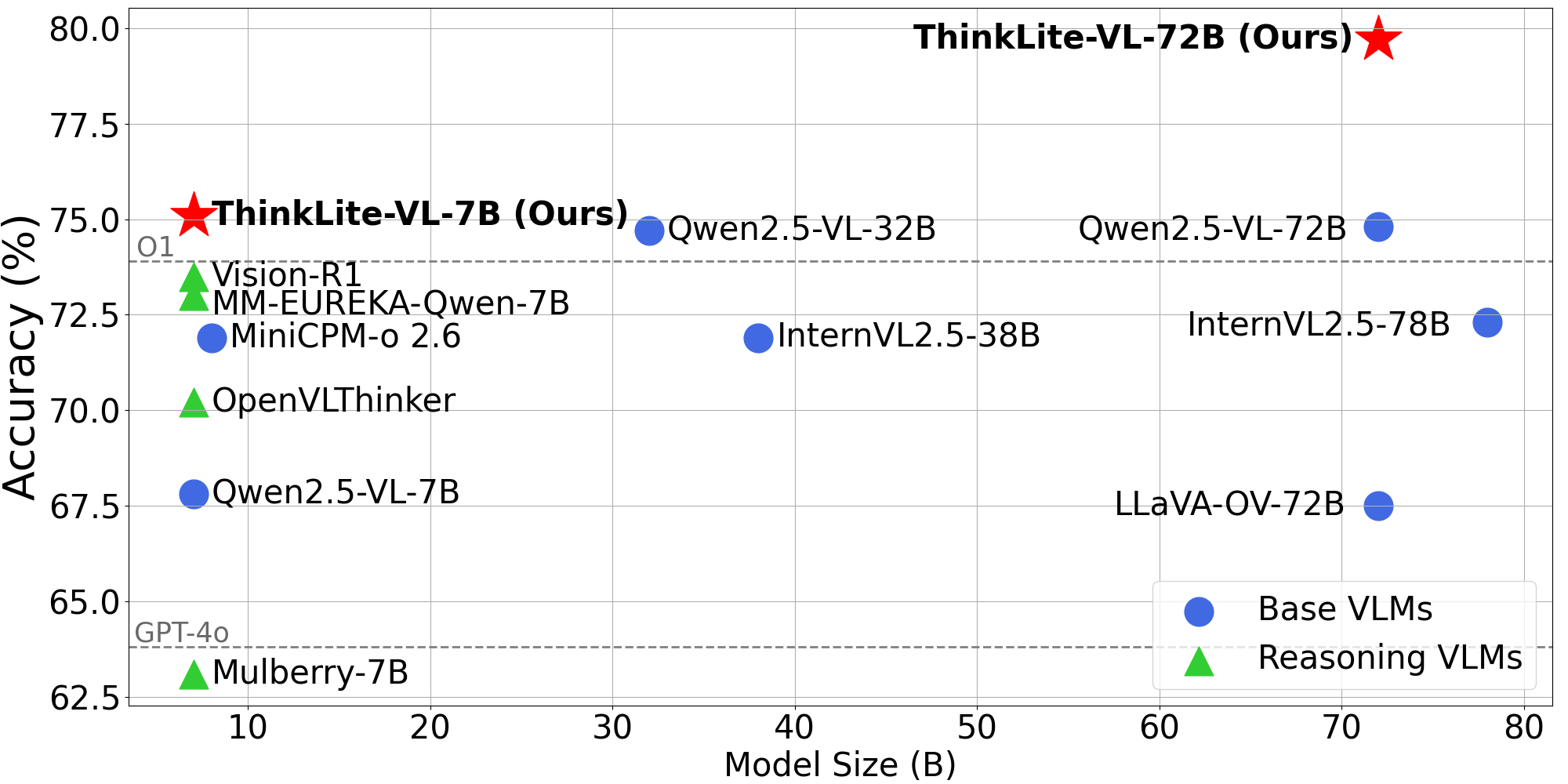
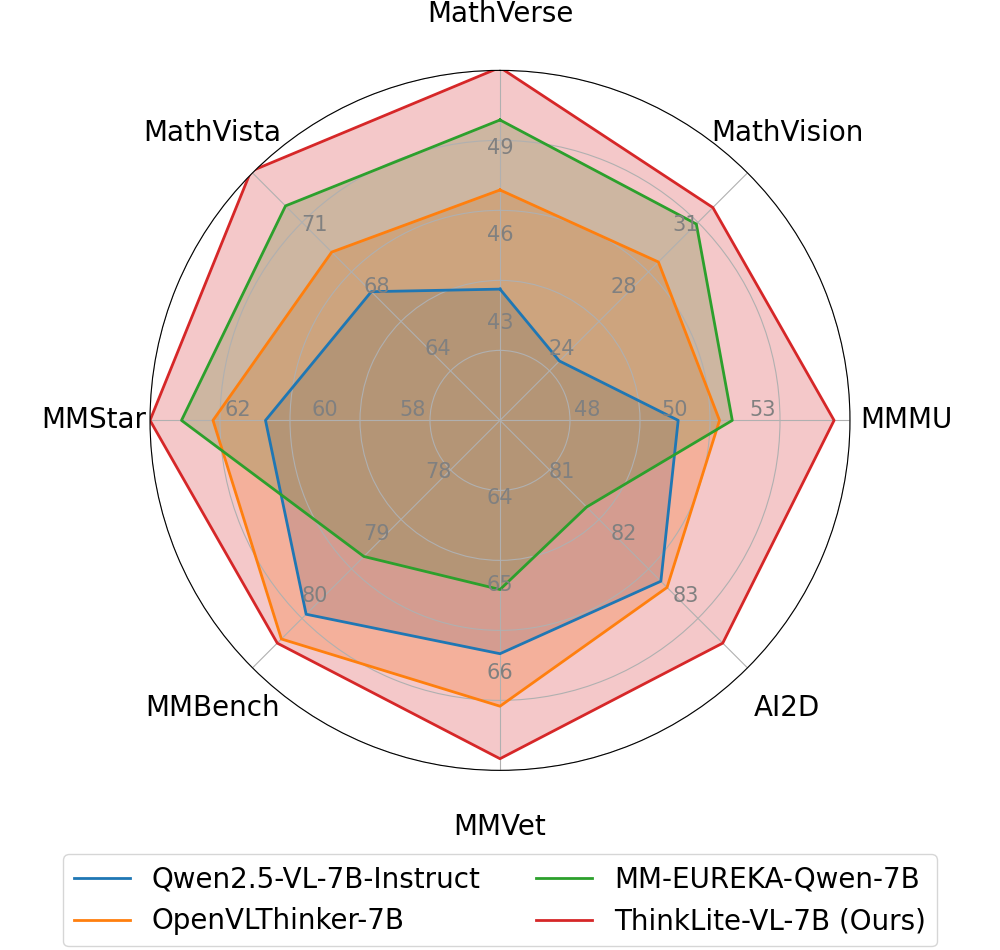
- ThinkLite-VL-7B achieves 75.1% on MathVista, a new SoTA for 7B models, surpassing GPT-4o (63.8%) and Qwen2.5-VL-72B (71.9%) on this benchmark.
- ThinkLite-VL-72B achieves 79.7% on MathVista, improving 4.42 points on average over the open-source SoTA.
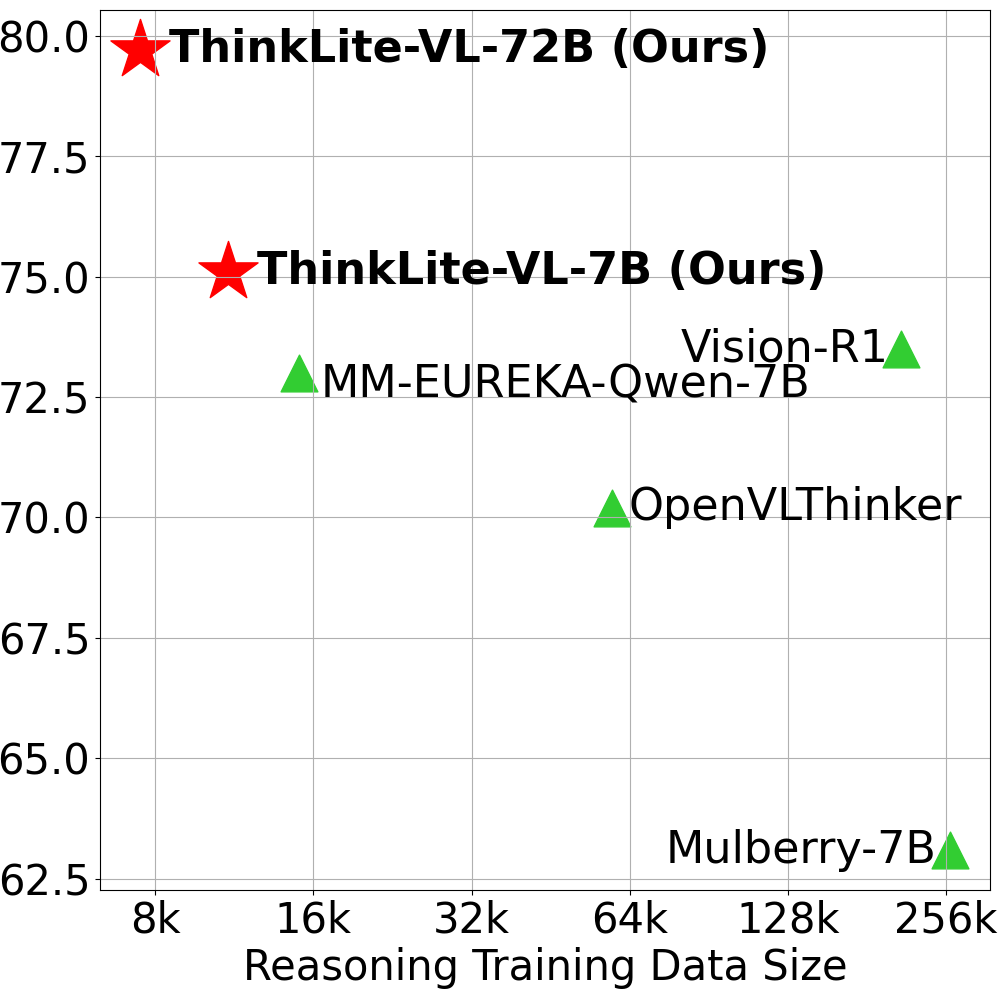
- Achieves these results using only 11k samples for the 7B model and 7.5k for the 72B model, an order of magnitude less data than typical instruction tuning sets.
Breakthrough Assessment
9/10
Achieves SoTA on major benchmarks (MathVista) with significantly less data and no distillation, challenging the prevailing paradigm that VLMs require massive SFT or teacher distillation for reasoning.