📝 Paper Summary
Audio-Language Models (ALMs)
Long Audio Understanding
Multi-Modal Reasoning
Audio Flamingo 2 enables expert-level reasoning and long-context audio understanding by combining a specialized curriculum, a robust new CLAP encoder, and a sliding-window mechanism into a parameter-efficient 3B language model.
Core Problem
Current Audio-Language Models fail at expert-level reasoning tasks and are limited to processing short audio clips (typically under 30 seconds) due to poor data quality and encoder limitations.
Why it matters:
- Expert reasoning is required for real-world applications like industrial anomaly detection and assistive technology, but models lag behind human performance.
- Existing Large Audio-Language Models (LALMs) prioritize foundational tasks (captioning/classification) over complex reasoning, leading to poor generalization on difficult benchmarks.
- The inability to process long audio (e.g., minutes vs. seconds) severely limits the utility of AI in analyzing real-world soundscapes and music tracks.
Concrete Example:
On the MMAU benchmark for expert-level audio reasoning, the advanced Gemini-1.5-Pro model achieves only 54.4% on sound and 48.5% on music subsets, highlighting the failure of current state-of-the-art models to grasp complex auditory contexts.
Key Novelty
Audio Flamingo 2 (AF2)
- Introduces AF-CLAP, an improved audio encoder trained with 'composition-aware negatives' to distinguish temporal order (A before B vs. B before A) and linguistic variations.
- Implements a sliding-window mechanism with gated cross-attention to process long audio (up to 5 minutes) without retraining the language model backbone.
- Uses 'AudioSkills', a massive synthetic dataset designed to teach specific reasoning skills (counting, temporal ordering) rather than just simple captioning.
Architecture
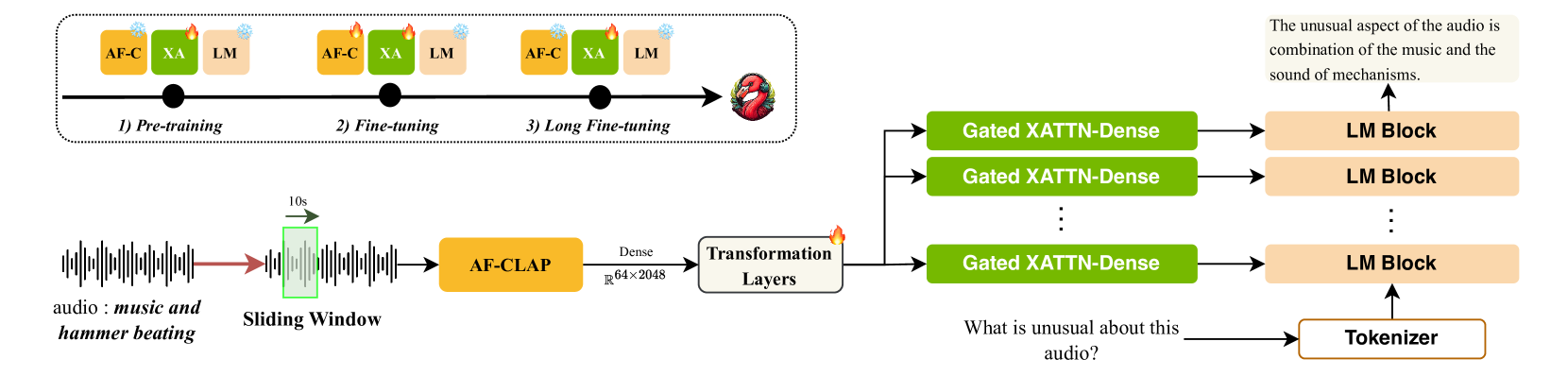
The AF2 architecture showing the flow from audio input to text generation.
Breakthrough Assessment
8/10
Significant advance in long-context audio processing (up to 5 mins) and expert reasoning. The construction of specialized datasets (AudioSkills, LongAudio) addresses a critical data gap.