📝 Paper Summary
Efficient Reasoning
Prompt Engineering
Inference Acceleration
Sketch-of-Thought improves LLM efficiency by replacing verbose Chain-of-Thought with concise, cognitively-inspired reasoning structures selected dynamically by a lightweight router.
Core Problem
Chain-of-Thought (CoT) prompting induces verbose natural language outputs, significantly increasing token usage and latency.
Why it matters:
- High computational overhead makes reasoning models expensive to deploy in budget-constrained environments
- Existing compression methods like rigid length constraints often degrade reasoning accuracy by cutting off necessary logic
- Latency-sensitive applications require faster inference without sacrificing the problem-solving depth of CoT
Concrete Example:
In mathematical reasoning, CoT might generate full sentences like 'First, we subtract the cost from the total...', whereas Sketch-of-Thought uses symbolic shorthand like 'Total - Cost = Remainder' to convey the same logic with fewer tokens.
Key Novelty
Adaptive Cognitive-Inspired Sketching
- Proposes three specific reasoning paradigms (Conceptual Chaining, Chunked Symbolism, Expert Lexicons) that mimic human cognitive shortcuts (associative memory, working memory chunking, expert schemas)
- Uses a lightweight router (DistilBERT) to analyze the input query and dynamically select the most efficient reasoning paradigm rather than using a one-size-fits-all prompt
Architecture
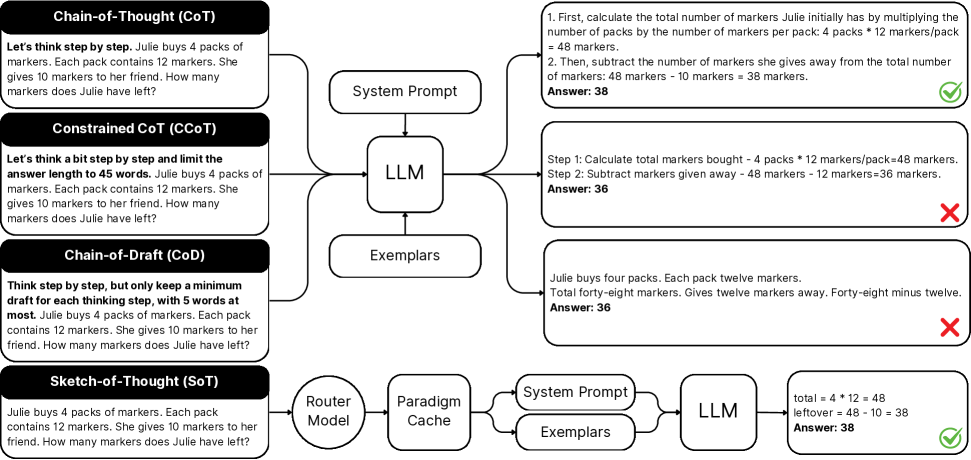
The end-to-end inference framework of Sketch-of-Thought.
Evaluation Highlights
- Reduces output token usage by ~74% on average (up to 84%) across 15 datasets compared to standard Chain-of-Thought
- +0.06% accuracy improvement on Qwen-2.5-32B (82.30% vs 82.24% CoT) while using 74% fewer tokens
- Maintains GPT-4o accuracy within 0.1% (84.55% vs 84.64%) while reducing token count by 76%
Breakthrough Assessment
7/10
Strong practical contribution for efficiency. While prompting strategies are common, the dynamic routing based on cognitive paradigms offers a principled way to balance brevity and accuracy across diverse domains.