📝 Paper Summary
Reward Modeling
Reinforcement Learning with Human Feedback (RLHF)
Chain-of-Thought Reasoning
RM-R1 formulates reward modeling as a reasoning task, using a chain-of-rubrics mechanism and a distillation-then-RL pipeline to enable interpretable, high-accuracy preference judgments.
Core Problem
Existing scalar reward models are opaque, while generative reward models often produce superficial reasoning that fails on complex tasks requiring multifaceted cognitive considerations.
Why it matters:
- Scalar reward models provide no justification for scores, limiting transparency and debugging.
- Current generative reward models struggle with deep reasoning, leading to suboptimal performance on hard tasks like math or code.
- Accurate reward modeling requires simulating consequences and navigating trade-offs, mirroring human grading processes.
Concrete Example:
In a reasoning task where a response contains a subtle logical error, a standard scalar reward model might assign a high score based on surface-level fluency. In contrast, RM-R1 first solves the problem itself, identifies the error through step-by-step verification, and then penalizes the response based on the correctness rubric.
Key Novelty
Reasoning Reward Models (ReasRMs) via Chain-of-Rubrics
- Treats reward modeling as a reasoning problem where the model must 'think' before judging.
- Uses a 'Chain-of-Rubrics' strategy: for chat, it self-generates evaluation criteria; for reasoning, it solves the problem first to establish ground truth.
- Combines reasoning-oriented distillation (from strong oracles) with Reinforcement Learning with Verifiable Rewards (RLVR) to optimize the judgment process.
Architecture
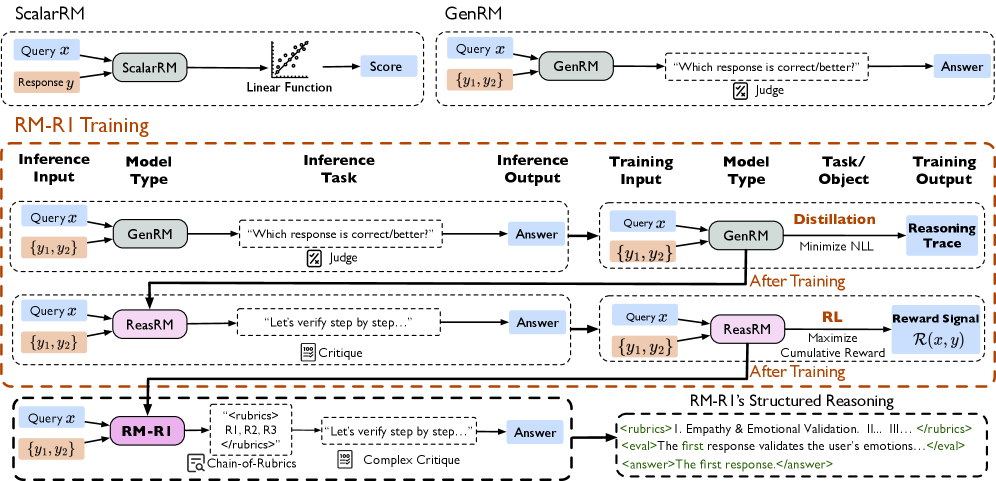
The overall training pipeline of RM-R1, illustrating the two-stage process: Reasoning Distillation followed by Reinforcement Learning.
Evaluation Highlights
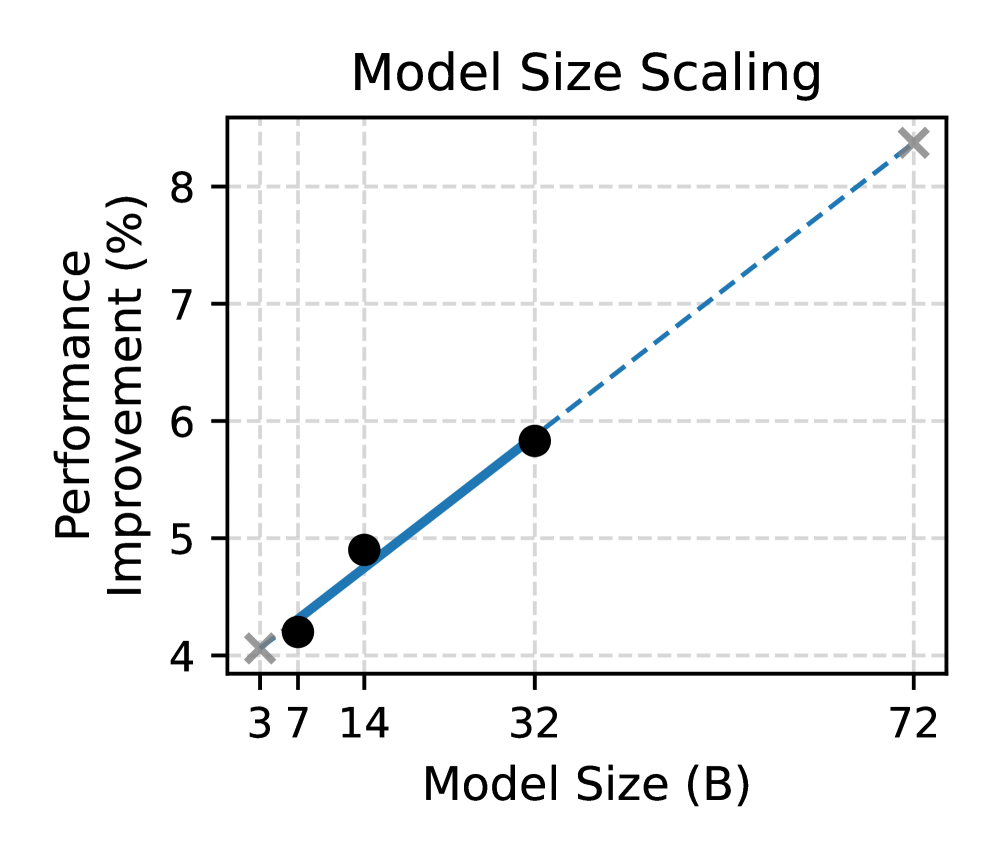
- RM-R1-DeepSeek-Distilled-Qwen-32B achieves state-of-the-art on RM-Bench (91.8% math, 74.1% code accuracy), outperforming GPT-4o.
- Outperforms much larger models (e.g., Nemotron-4-340B-Reward, INF-ORM-Llama3.1-70B) by up to 4.9% on average across three benchmarks.
- Instruct-based models reach competitive performance using only 8.7K distillation examples, compared to 800K used in prior work like DeepSeek-Distilled.
Breakthrough Assessment
9/10
Establishes a new SOTA for reward modeling by successfully integrating long-chain reasoning. The performance gains over significantly larger models (70B/340B) and the novel Chain-of-Rubrics methodology mark a significant advance.