📊 Experiments & Results
Evaluation Setup
Review of existing benchmarks in Multimodal Reasoning
Benchmarks:
- MMMU (Multimodal Multi-discipline Understanding)
- MathVista (Visual Mathematical Reasoning)
- ScienceQA (Scientific Question Answering)
Metrics:
- Not explicitly reported in the paper
- Statistical methodology: Not explicitly reported in the paper
Experiment Figures
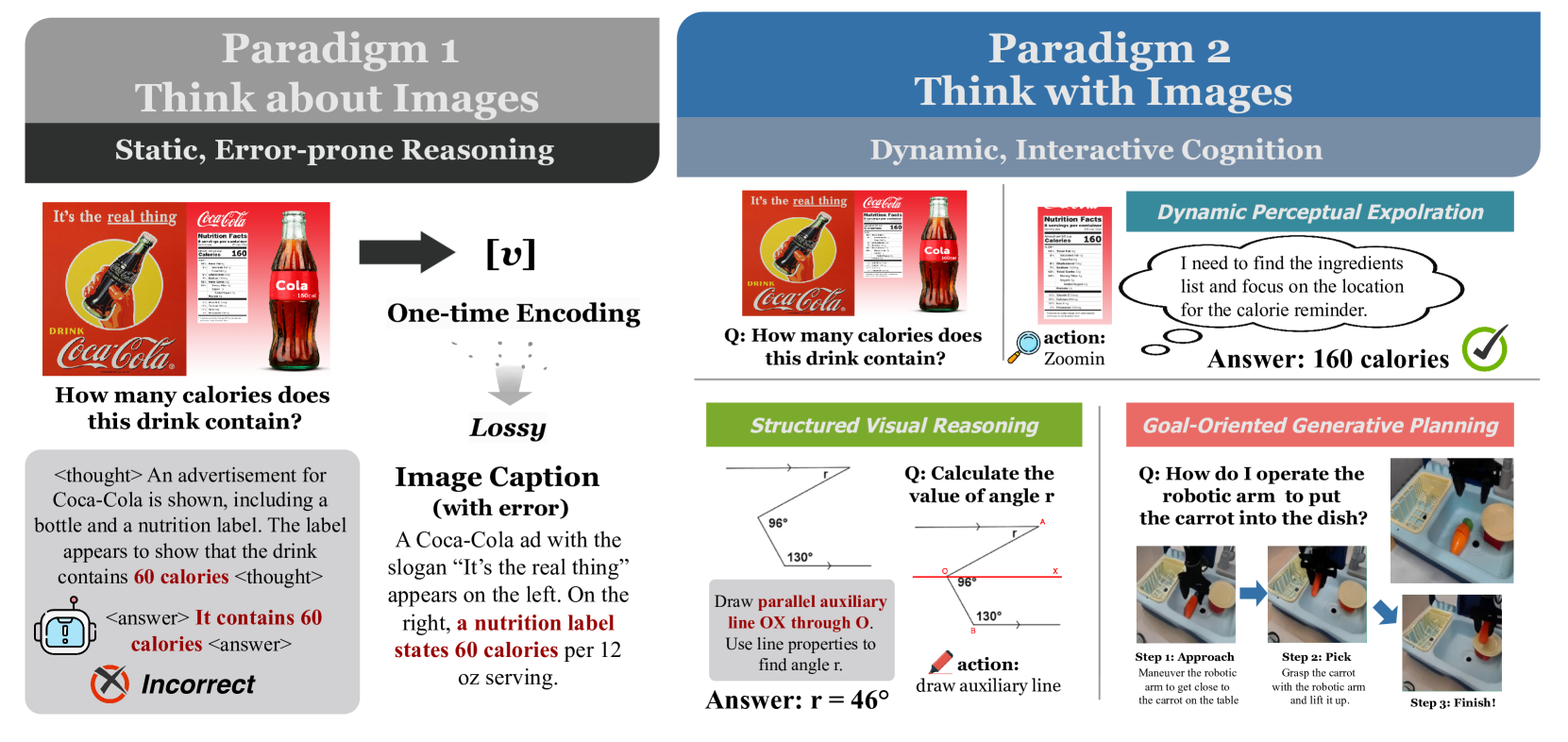
Conceptual comparison between 'Thinking about Images' and 'Thinking with Images'.
Main Takeaways
- The field is moving from static perception ('Thinking about') to dynamic manipulation ('Thinking with'), driven by the need for fine-grained spatial and physical reasoning.
- A three-stage evolution is observed: initially relying on external tools (Stage 1), then code generation (Stage 2), and finally intrinsic image generation (Stage 3).
- Visual simulation allows models to 'outsource' validation to the consistency of the visual world (e.g., checking if a generated plan looks physically impossible).
- Major challenges remain in computational efficiency and preventing visual hallucinations from poisoning the reasoning chain.