📊 Experiments & Results
Evaluation Setup
Zero-shot evaluation of 9 SoTA MLLMs using both Direct Answering and Chain-of-Thought (CoT) prompting
Benchmarks:
- EMMA (Multimodal Reasoning (Math, Physics, Chemistry, Coding)) [New]
Metrics:
- Accuracy (%)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Performance on the balanced subset of EMMA shows a significant gap between the best reasoning model (o1), standard MLLMs, and human experts. | ||||
| EMMA (Balanced Subset) | Accuracy | 37.25 | 45.75 | +8.50 |
| EMMA (Balanced Subset) | Accuracy | 77.75 | 45.75 | -32.00 |
Experiment Figures

Examples of EMMA tasks across domains: Math (Pattern Inference), Physics (Visual Decomposition), Chemistry (Reaction Simulation), and Coding (3D Visualization)
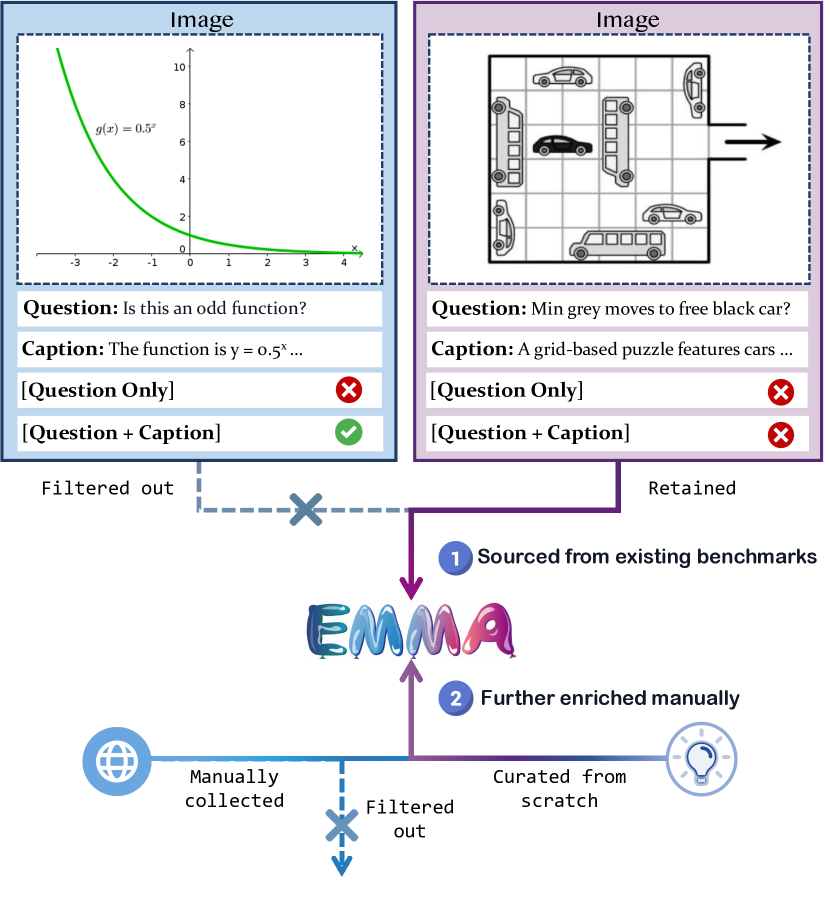
The EMMA data construction and filtering pipeline
Main Takeaways
- Chain-of-Thought (CoT) prompting often fails or negatively impacts performance on visual-heavy tasks, as models hallucinate text reasoning that contradicts visual evidence
- Test-time compute scaling (e.g., Best-of-N) provides minimal gains because models struggle to generate any valid visual reasoning path, unlike in text-only tasks where scaling is effective
- Models perform particularly poorly on tasks requiring spatial simulation (e.g., 3D transformations, reaction mechanisms), highlighting a fundamental lack of 'visual physics' understanding