📝 Paper Summary
Medical Vision-Language Models (Med-VLM)
Reinforcement Learning for VLM Post-Training
Med-R1 applies Group Relative Policy Optimization (GRPO) to medical vision-language models, demonstrating that reinforcement learning improves generalization across eight imaging modalities better than supervised fine-tuning, especially when reasoning is generated after the answer.
Core Problem
Supervised fine-tuning (SFT) for medical VLMs leads to shortcut learning and poor generalization due to scarcity of high-quality reasoning annotations, while standard Chain-of-Thought (CoT) often induces hallucinations in medical domains.
Why it matters:
- Medical imaging requires precise, clinically coherent reasoning across diverse modalities (CT, MRI, etc.), which general VLMs struggle to provide consistently.
- Curating high-quality expert CoT annotations is prohibitively expensive, limiting the effectiveness of SFT-based approaches.
- Existing medical VLMs act as 'black boxes' with limited interpretability, hindering clinical adoption where explainability is crucial.
Concrete Example:
Diagnosing a lung nodule requires multi-step analysis (localization, morphology, context). A standard SFT model might memorize a specific texture shortcut from training data, failing when applied to a different scanner or modality, whereas Med-R1 learns generalizable reasoning rules via RL.
Key Novelty
RL-driven Medical Adaptation with 'Think-After' Reasoning
- Adapts Group Relative Policy Optimization (GRPO) to medical VQA, using rule-based rewards (format and accuracy) to guide learning without expensive expert CoT annotations.
- Introduces 'Think-After' reasoning: the model predicts the answer first, then generates a rationale, avoiding the hallucinations common in 'Think-Before' approaches while preserving interpretability.
Architecture
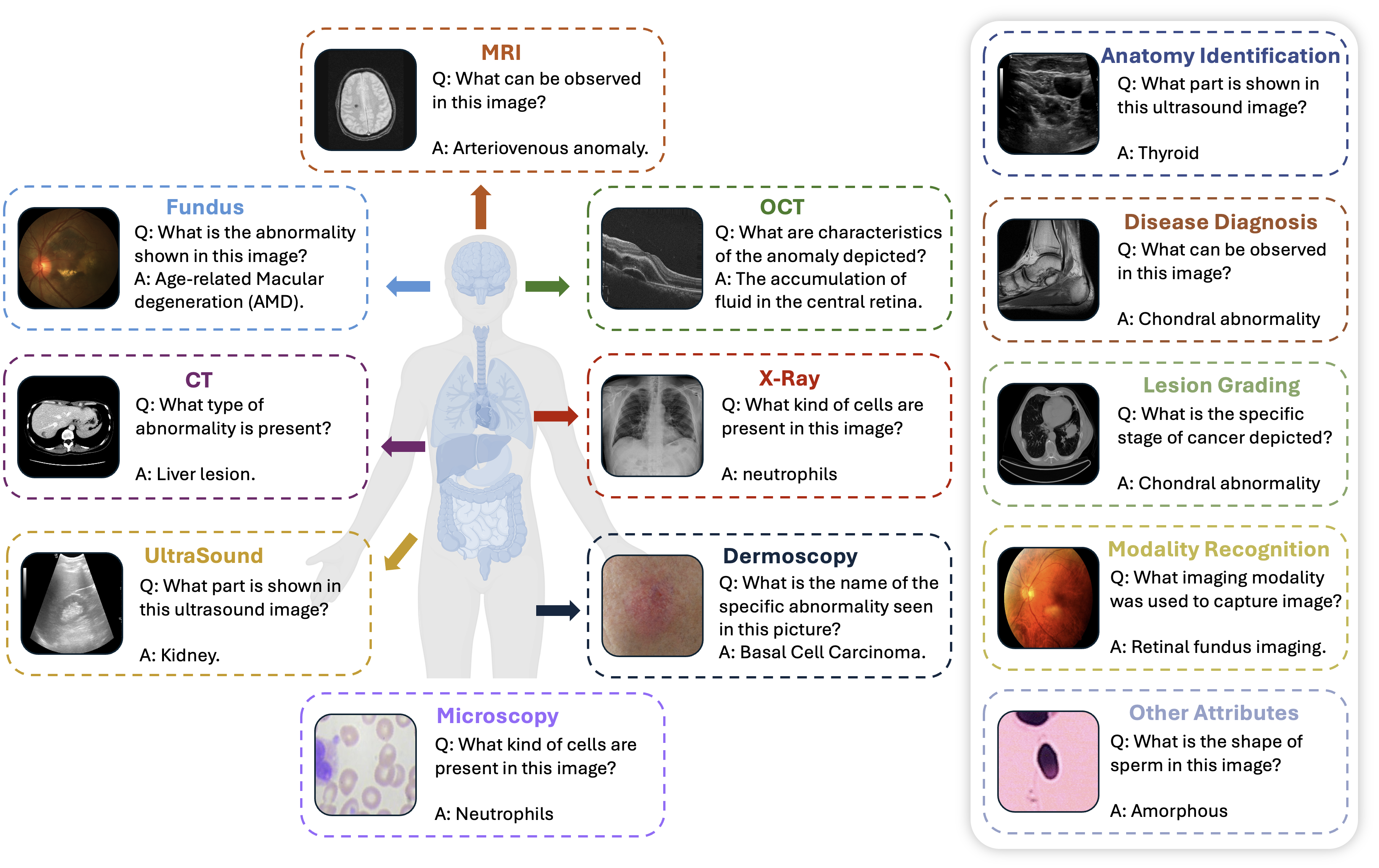
Overview of Med-R1 framework performance across 8 modalities compared to baselines.
Evaluation Highlights
- +29.94% improvement in average accuracy over the base model Qwen2-VL-2B across eight medical imaging modalities.
- Outperforms the 72B-parameter Qwen2-VL-72B model (36x larger) in average accuracy (69.91% vs 68.05%).
- +32.06% improvement in question-type generalization accuracy compared to the base Qwen2-VL-2B model.
Breakthrough Assessment
8/10
Strong empirical results showing a 2B model outperforming a 72B model via RL adaptation. The 'Think-After' finding challenges standard CoT assumptions in specialized domains, offering a practical path for interpretable medical AI.