📝 Paper Summary
Neural Theorem Proving
Formal Mathematics (Lean 4)
Reinforcement Learning for Reasoning
Kimina-Prover adapts a large-scale reinforcement learning pipeline to formal mathematics, using a structured reasoning pattern to enable internal exploration and achieving state-of-the-art Lean 4 proof generation without external search.
Core Problem
Existing neural theorem provers rely on computationally expensive external search algorithms (BFS, MCTS) and fail to capture deep structured reasoning, resulting in poor scaling with model size.
Why it matters:
- External search methods like BFS/MCTS introduce significant computational overhead and complexity, limiting scalability
- Standard supervised fine-tuning lacks the ability to elicit the non-linear, sophisticated reasoning required for complex formal proofs
- Prior formal math models have not shown clear performance improvements when scaling model size, unlike informal reasoning models
Concrete Example:
General reasoning models like OpenAI's o3 achieve 0% on the formal IMO subset of miniF2F because they default to informal, unverifiable answers. In contrast, Kimina-Prover generates valid Lean 4 code by internally verifying and refining steps, achieving 40% on the same subset.
Key Novelty
Reasoning-Driven Exploration with Formal Reasoning Patterns
- Replaces external tree search (BFS/MCTS) with internal 'reasoning-driven exploration' where the model explores the proof space via long chain-of-thought tokens
- Enforces a specific 'formal reasoning pattern' that interleaves informal mathematical thought with formal Lean code blocks, aligning intuition with verification
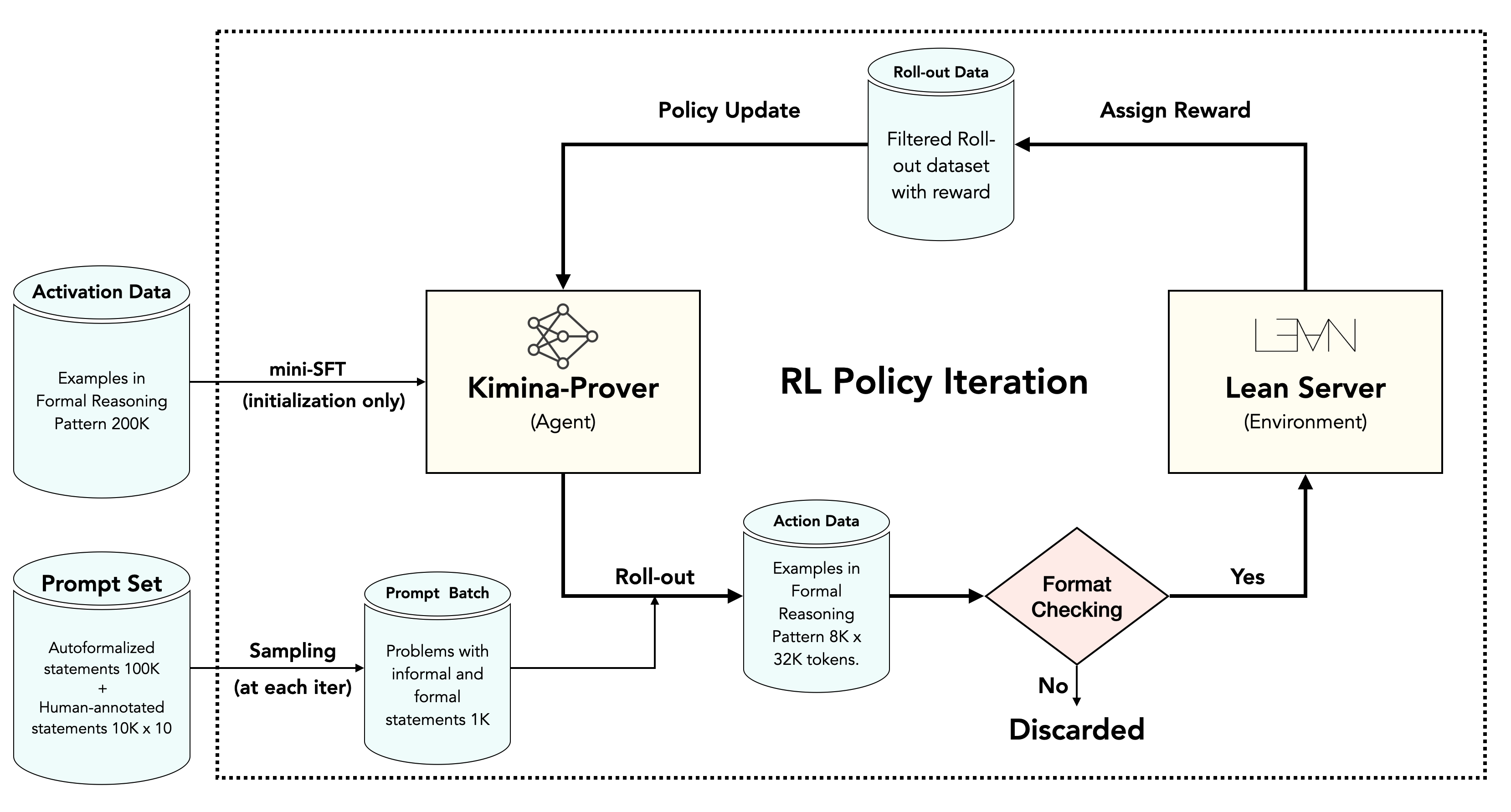
- Applies the Kimi k1.5 reinforcement learning pipeline to formal math, utilizing a large-scale autoformalized dataset and binary correctness rewards
Architecture
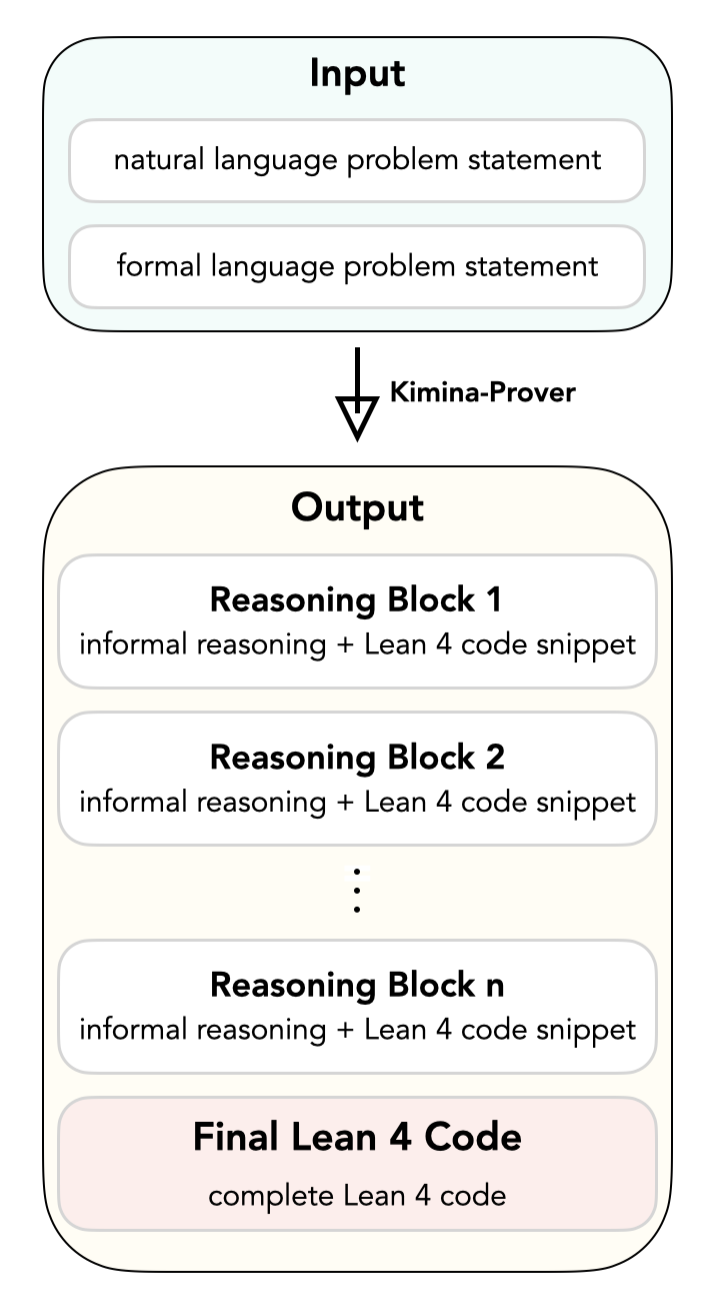
The Reinforcement Learning pipeline and the 'Formal Reasoning Pattern'.
Evaluation Highlights
- Achieves 80.7% accuracy (pass@8192) on miniF2F-test, setting a new state-of-the-art and surpassing the previous best (BFS Prover) of 72.95%
- Demonstrates high sample efficiency with 52.94% pass@1 and 68.85% pass@32 on miniF2F, outperforming many search-based baselines requiring thousands of samples
- Shows clear performance scaling with model size (1.5B → 7B → 72B), with the 72B model outperforming the 7B version by +7.87% at pass@8192
Breakthrough Assessment
9/10
First system to demonstrate clear scaling laws for formal theorem proving and achieve >80% on miniF2F without external search algorithms. Effectively bridges informal and formal reasoning via RL.