📝 Paper Summary
Multimodal Reasoning
Reinforcement Learning for LLMs
Visual Question Answering
VisualThinker-R1-Zero replicates the emergent reasoning patterns of DeepSeek R1 in a small multimodal model by applying reinforcement learning directly to a non-instruction-tuned base model.
Core Problem
Existing attempts to replicate DeepSeek R1's reasoning capabilities in multimodal models fail to reproduce the 'aha moment' and often result in trivial, superficial reasoning traces when applied to instruction-tuned models.
Why it matters:
- Multimodal models often lack the ability to autonomously develop sophisticated problem-solving strategies (self-reflection, correction) found in text-only reasoning models
- Relying on Supervised Fine-Tuning (SFT) before RL appears to constrain the model's exploration, preventing the emergence of genuine reasoning behaviors
Concrete Example:
When applying RL to an instruction-tuned model, the model generates trivial traces like '<think> I will answer the question </think> <answer> ... </answer>' rather than actual reasoning. Attempts to force longer reasoning with length rewards result in meaningless text generation (reward hacking).
Key Novelty
VisualThinker-R1-Zero (Direct RL on Base VLM)
- Bypasses Supervised Fine-Tuning (SFT) entirely, applying Group Relative Policy Optimization (GRPO) directly to a raw, pre-trained base model (Qwen2-VL-2B)
- Uses simple rule-based rewards (accuracy + format) to induce spontaneous self-reflection and increased reasoning length, replicating the 'aha moment' observed in text-only R1-Zero
Architecture
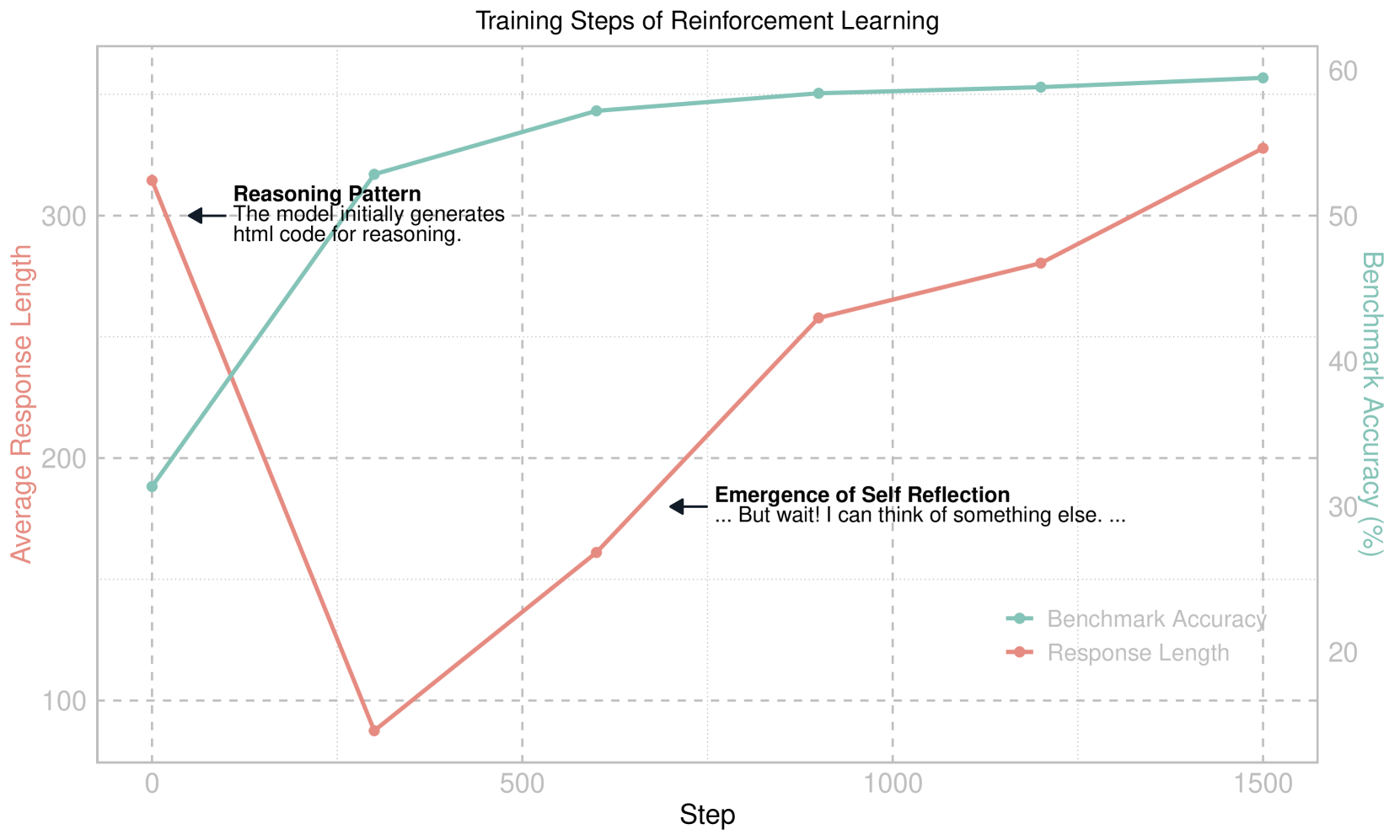
Conceptual flow of the training process showing the emergence of reasoning length and performance
Evaluation Highlights
- Achieves 59.47% accuracy on CVBench, outperforming the Qwen2-VL-2B base model by ~30% and exceeding the SFT version by ~2%
- Demonstrates a ~27% performance advantage over the SFT baseline on BLINK and VSR spatial reasoning benchmarks
- Successfully induces the 'aha moment' (self-correction and increased thinking time) which failed to emerge in instruction-tuned baselines
Breakthrough Assessment
9/10
Significant finding: identifying that SFT hinders the 'aha moment' in multimodal RL is a crucial insight. Successfully replicating R1-Zero dynamics on a small 2B model makes advanced reasoning research accessible.