📝 Paper Summary
Medical Benchmarking
Multimodal Reasoning
Clinical Decision Making
MedXpertQA introduces a challenging medical benchmark constructed from specialty board exams and diverse clinical images to evaluate expert-level reasoning capabilities where current models like GPT-4o struggle.
Core Problem
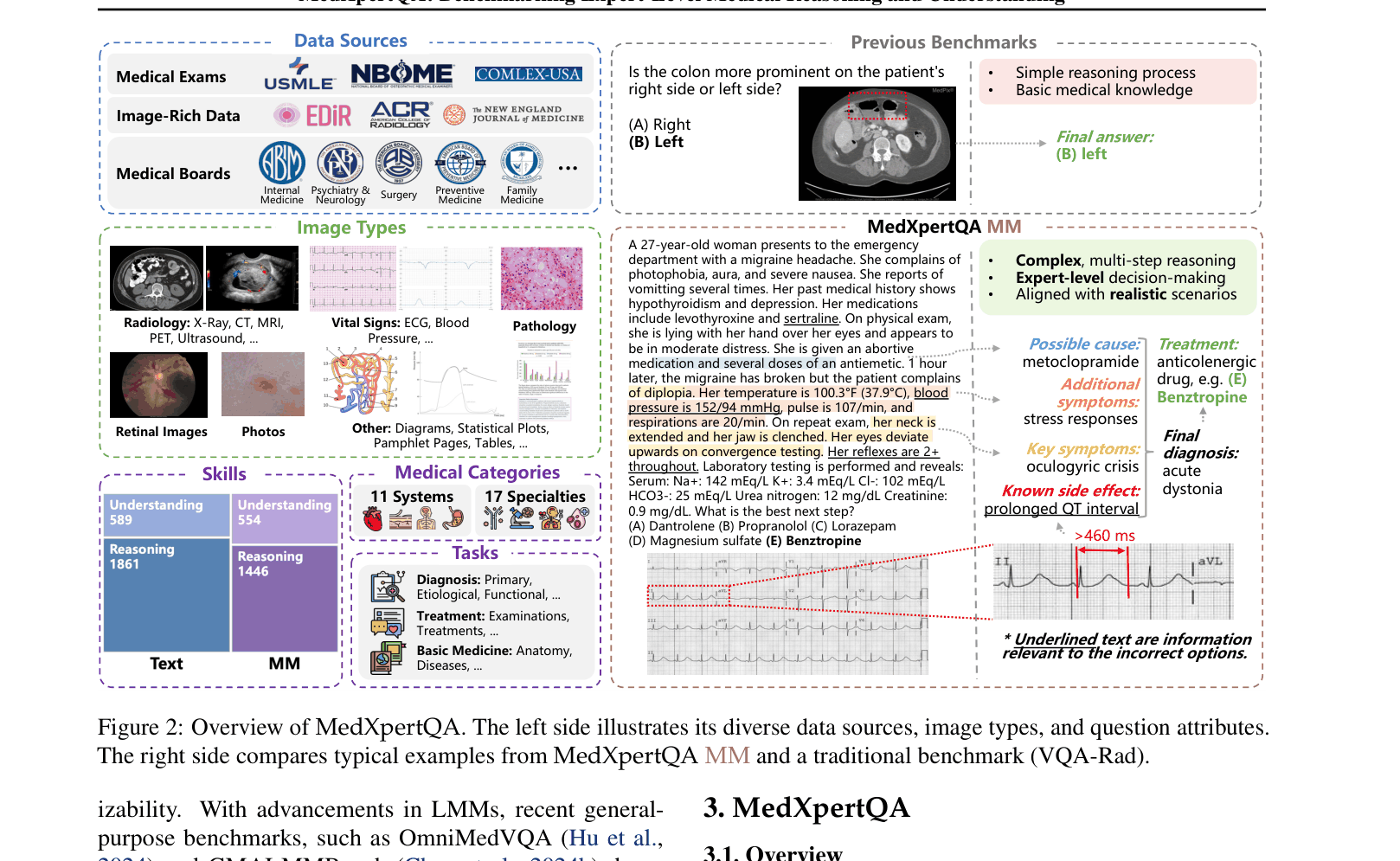
Existing medical benchmarks are either too easy (saturated by current models) or lack clinical realism, relying on general licensing exams or simple caption-based multimodal questions rather than complex diagnostic tasks.
Why it matters:
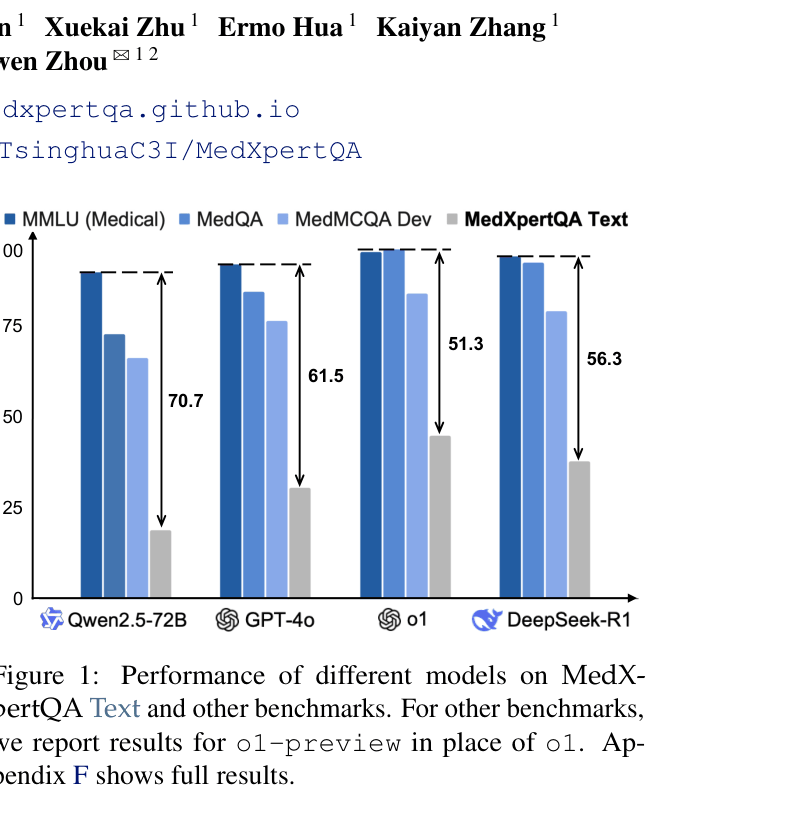
- Current benchmarks like MedQA and MMLU-Medical are saturated, with models like o1 achieving ~99% accuracy, making it impossible to distinguish true expert reasoning from memorization
- Traditional multimodal benchmarks use simple QA pairs generated from captions, failing to simulate real-world clinical workflows where doctors must synthesize patient history, vitals, and imaging
Concrete Example:
A traditional benchmark might ask 'What organ is this?' given an MRI. MedXpertQA presents a 27-year-old patient's history of migraines and hypothyroidism, vital signs showing hypertension, and a lab report, then asks for the best next treatment step (e.g., 'Benztropine') among 5-10 plausible distractors.
Key Novelty
MedXpertQA (Benchmark for Expert-Level Medical Reasoning)
- Incorporates questions from 17 specific specialty board exams (e.g., Family Medicine, Addiction Medicine) rather than just general licensing exams, increasing difficulty and domain specificity
- Implements a rigorous filtering pipeline using 'AI Experts' (models) and 'Human Experts' (using adaptive Brier score thresholds) to ensure only non-trivial questions remain
- Utilizes data synthesis (question rewriting and option augmentation) to minimize data leakage risks while preserving clinical accuracy through licensed physician review
Architecture
The construction pipeline of MedXpertQA, detailing data sources, filtering steps, and the final dataset composition.
Evaluation Highlights
- o1 achieves 49.89% average accuracy, significantly outperforming GPT-4o (35.96%) and pre-licensed human experts (43.92%), yet remains below 50%, indicating high difficulty
- DeepSeek-R1 scores 37.76% on the Text subset, outperforming GPT-4o (30.37%) and demonstrating the value of inference-time scaling for medical reasoning
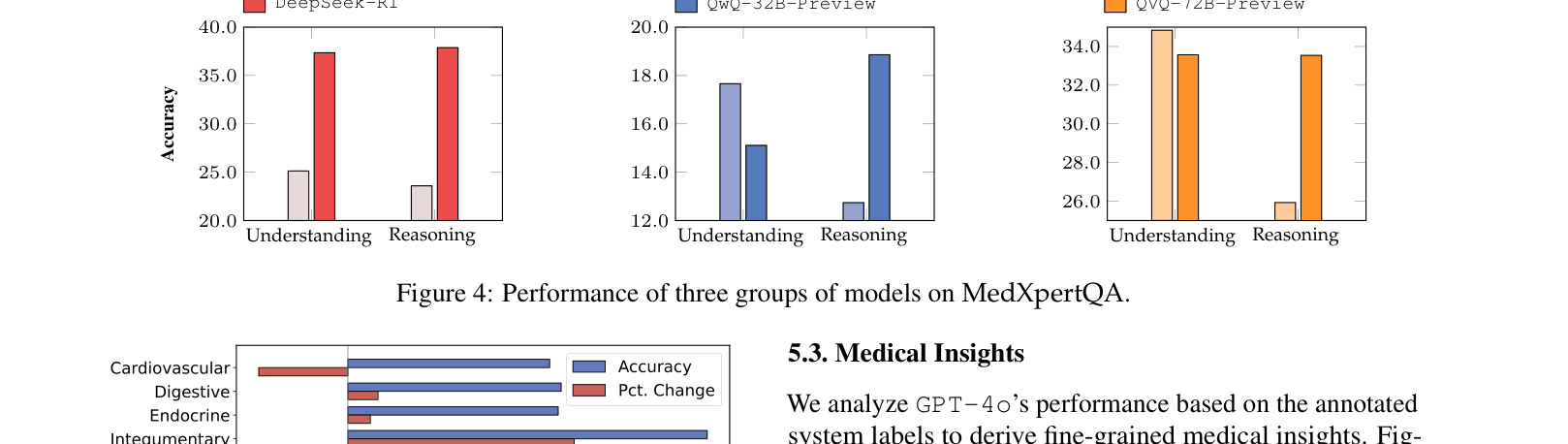
- Multimodal performance gap: GPT-4o (42.80%) outperforms Qwen2.5-VL-72B (29.95%) by a large margin on the MM subset, highlighting proprietary model dominance in visual medical tasks
Breakthrough Assessment
8/10
Significantly raises the bar for medical AI by addressing saturation in existing benchmarks. The inclusion of specialty boards and rigorous leakage prevention makes it a robust standard for next-gen reasoning models.