📝 Paper Summary
Spatial Reasoning
Multimodal Reasoning
Chain-of-Thought Prompting
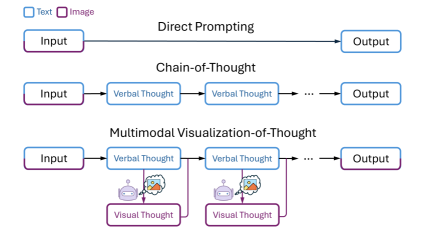
MVoT enables Multimodal LLMs to generate internal mental images alongside text during reasoning, significantly improving robustness in complex spatial tasks where text-only descriptions fail.
Core Problem
Text-only Chain-of-Thought (CoT) struggles with complex spatial reasoning because text is an inefficient and error-prone medium for describing intricate spatial layouts and dynamic environment updates.
Why it matters:
- Current LLMs perform poorly on spatial tasks (like navigation) when relying solely on verbal reasoning.
- Textual coordinates often fail to capture visual patterns, leading to hallucinated positions or objects.
- Humans naturally use dual coding (visual and verbal) for reasoning, a capability lacking in standard text-based CoT.
Concrete Example:
In the FrozenLake task, Chain-of-Thought (CoT) frequently miscalculates the agent's position because it relies on tracking text coordinates of 'holes'. On a 6x6 grid, CoT accuracy drops to ~39% due to these textual description errors, whereas MVoT generates an image of the grid to accurately track the safe path.
Key Novelty
Multimodal Visualization-of-Thought (MVoT)
- Instead of reasoning only in text, the model generates interleaved image tokens (visualizations) that represent the intermediate state of the environment (e.g., current maze layout).
- Introduces 'Token Discrepancy Loss' to align the vector spaces of the text tokenizer and the image tokenizer, ensuring high-quality visual generation during the reasoning process.
Architecture
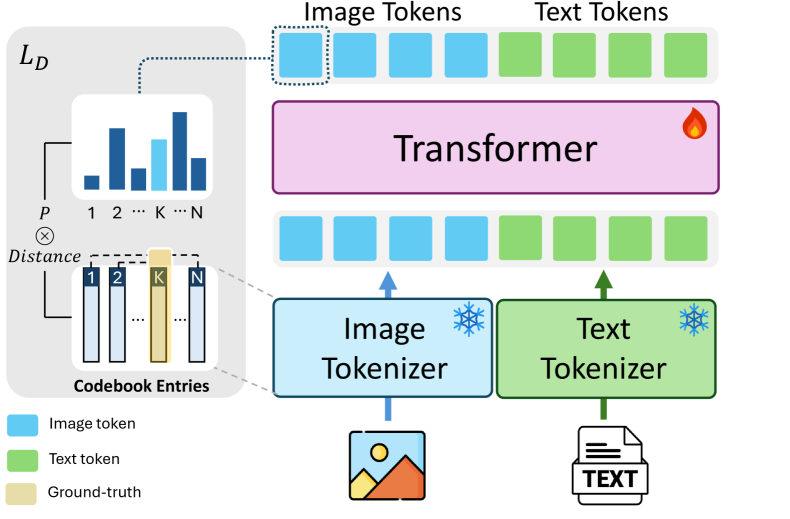
The architecture of MVoT implementation using Chameleon-7B, highlighting the unified transformer and the Token Discrepancy Loss.
Evaluation Highlights
- Outperforms traditional Chain-of-Thought (CoT) by over 20% in challenging scenarios (e.g., complex FrozenLake grids).
- Achieves 85.60% accuracy on FrozenLake, surpassing both Direct prompting (~78%) and CoT (which performs worse than Direct).
- Maintains >83% accuracy on complex 6x6 grids where CoT performance collapses to 39.11%.
Breakthrough Assessment
8/10
A significant step towards 'dual-system' reasoning (verbal + visual) in MLLMs. While raw performance on simple tasks is comparable to CoT, the robustness gain in complex spatial environments is massive.