📝 Paper Summary
Logical Reasoning Evaluation
Constraint Satisfaction Problems (CSPs)
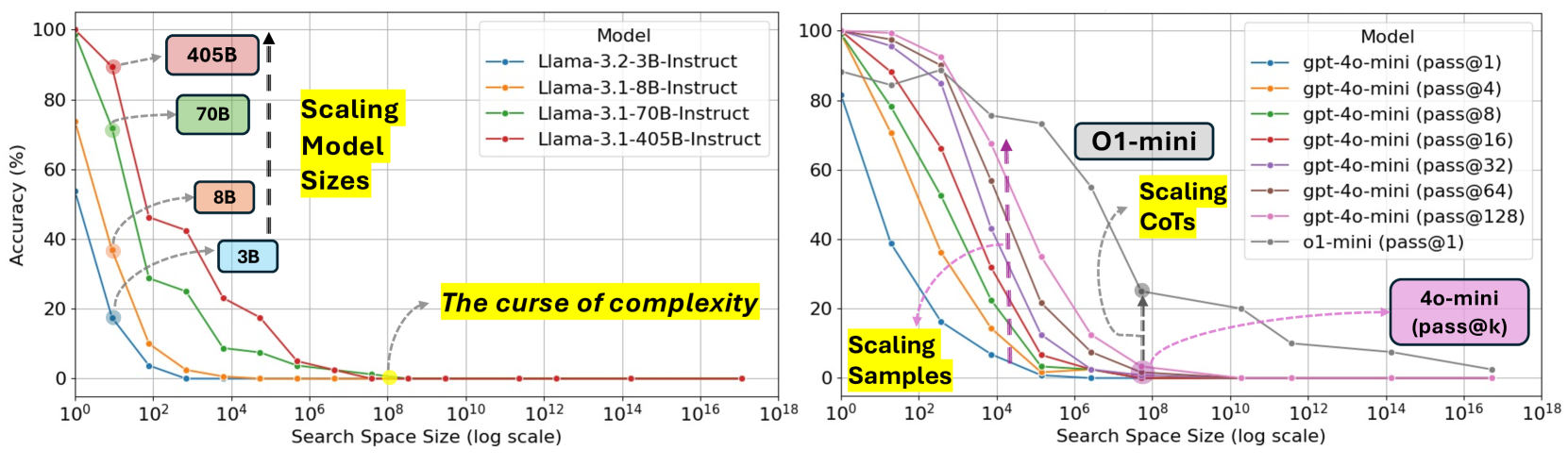
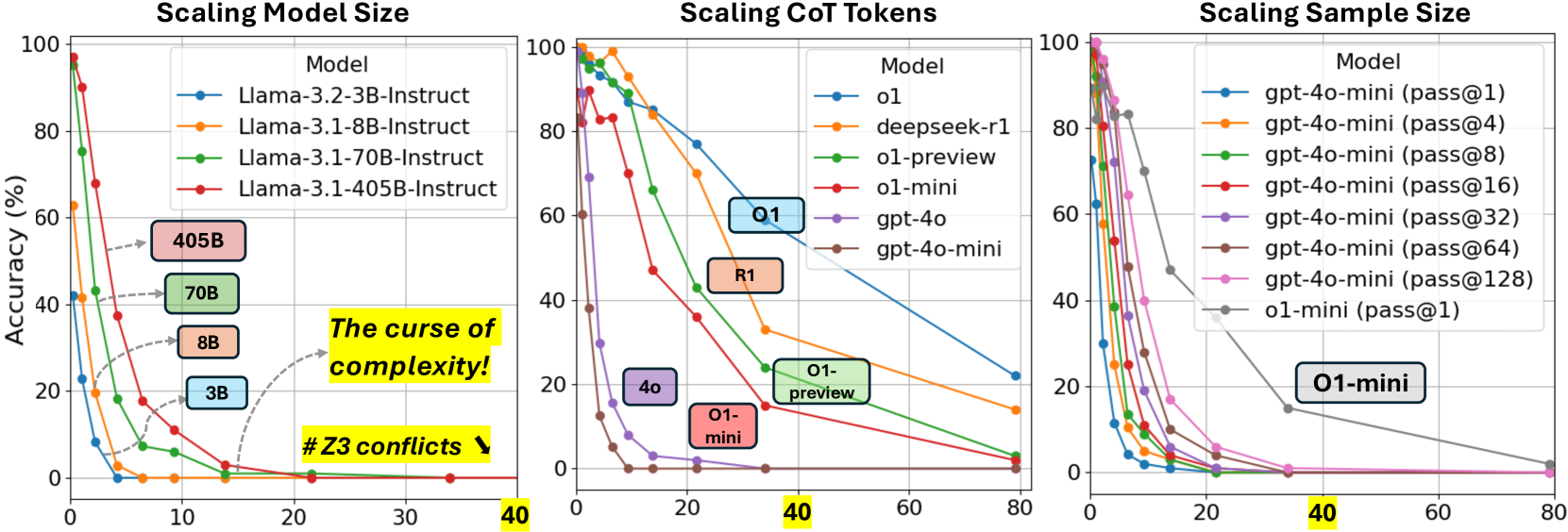
The paper introduces ZebraLogic, a benchmark of 1,000 logic grid puzzles, revealing that current LLM reasoning accuracy collapses as problem complexity increases, a limitation not solved by model size alone.
Core Problem
Current LLMs struggle with complex deductive problems requiring non-monotonic reasoning (backtracking), and existing benchmarks often fail to isolate pure reasoning from domain knowledge or lack controllable complexity.
Why it matters:
- Systematic reasoning underpins real-world applications like task planning, scheduling, and resource allocation
- Understanding scaling limits is critical to determine if larger models naturally solve reasoning or if architectural changes are needed
- Data leakage in existing benchmarks makes it difficult to assess true reasoning versus memorization
Concrete Example:
In a 4x5 grid puzzle with >10^7 possibilities, a model might correctly deduce initial assignments but fail when a later clue contradicts an earlier assumption, requiring it to backtrack and revise—something standard LLMs fail to do, leading to 0% accuracy on high-complexity tasks.
Key Novelty
ZebraLogic: A Controllable Complexity Reasoning Benchmark
- Formulates logical reasoning tasks as Constraint Satisfaction Problems (CSPs) specifically using Logic Grid Puzzles, allowing programmatic generation of unique-solution puzzles
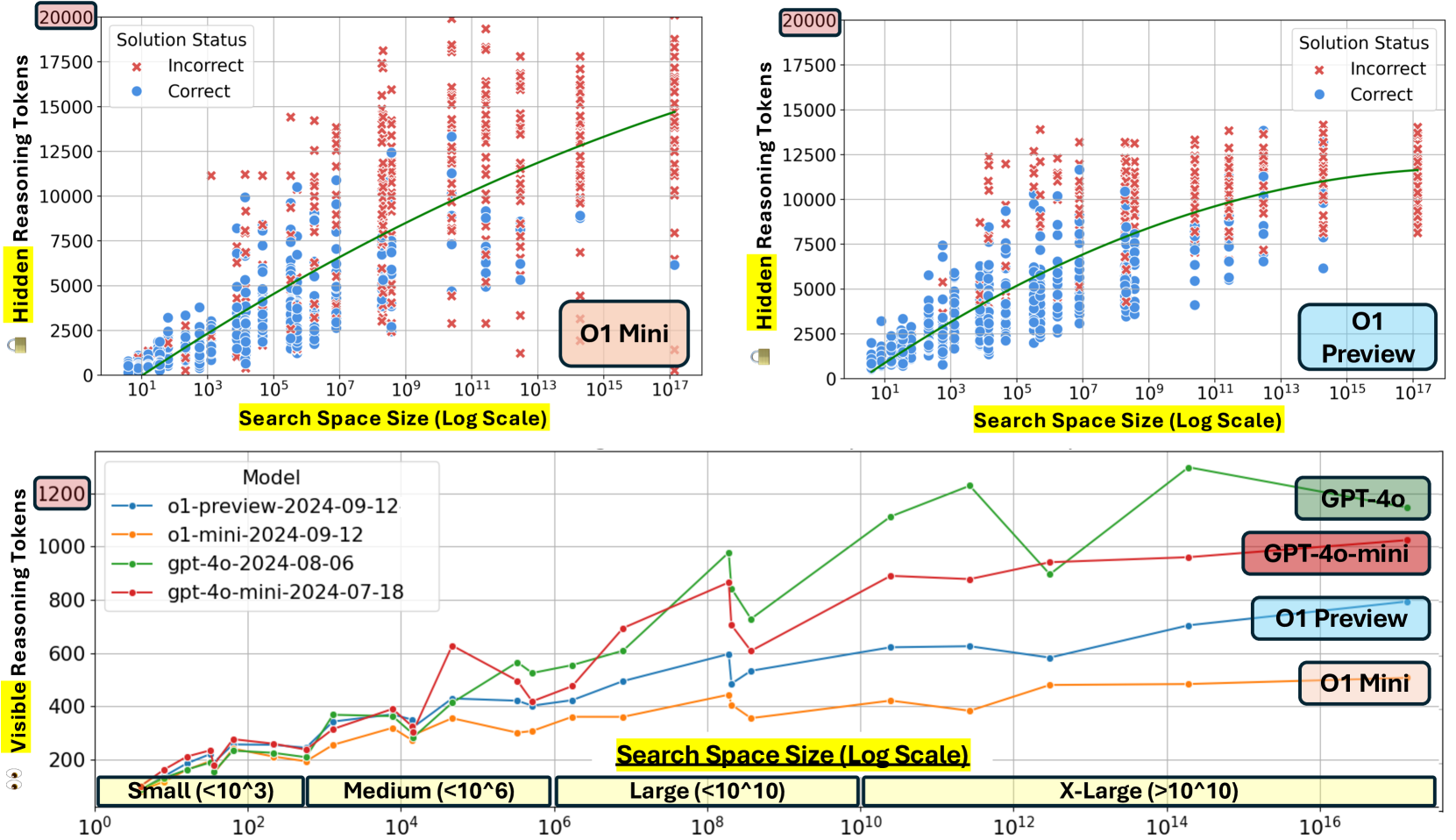
- Introduces two precise complexity metrics: search space size (total valid configurations) and Z3 conflict count (backtracking steps required by a solver), to quantify difficulty
- Identifies the 'Curse of Complexity': a threshold (e.g., search space > 10^7) where performance drops to near zero regardless of model size
Architecture
Conceptual flowchart of the ZebraLogic evaluation framework and the 'Curse of Complexity'
Evaluation Highlights
- Llama-3.1-405B accuracy drops from ~90% on trivial puzzles to <20% on puzzles with search spaces > 10^7
- Reasoning-specialized models (OpenAI o1-mini) achieve significantly higher accuracy (~80% on hard puzzles) by generating ~10x more reasoning tokens than standard models
- Best-of-128 sampling improves performance but fails to break the 'curse of complexity' on the hardest puzzles compared to increasing chain-of-thought length
Breakthrough Assessment
9/10
Establishes a rigorous, contamination-free framework for reasoning evaluation and empirically demonstrates the 'curse of complexity,' shifting the focus from model scaling to inference-time compute.