📝 Paper Summary
Efficient Reasoning
Chain-of-Thought (CoT) Optimization
Post-training for LLMs
DAST enables reasoning models to autonomously adjust their Chain-of-Thought length by training on preference pairs derived from a novel Token Length Budget metric that scales with problem difficulty.
Core Problem
Slow-thinking reasoning models (like o1 or DeepSeek-R1) suffer from 'overthinking,' generating excessively long reasoning chains for simple problems, which wastes computational resources.
Why it matters:
- Inefficient resource utilization increases latency and cost for end-users
- Existing solutions (uniform length penalties) indiscriminately shorten reasoning, causing performance degradation on complex tasks that require deep thinking
- Users suffer information overload from redundant reasoning steps on trivial questions
Concrete Example:
DeepSeek-R1 consumes over 1000 tokens to solve the simple equation '3x + 7=22, x=?', whereas a standard LLM uses only 58 tokens. DAST aims to align the token usage with the actual difficulty of the prompt.
Key Novelty
Difficulty-Adaptive Slow Thinking (DAST) Framework
- Introduces 'Token Length Budget' (TLB), a metric quantifying difficulty by combining sampling accuracy and response length distribution (harder problems get larger budgets)
- Implements budget-aware reward shaping that penalizes correct answers exceeding the TLB (overthinking) while rewarding insufficient incorrect answers that fall short of the budget (underthinking)
- Constructs 'Dual-Correct' and 'Dual-Incorrect' preference pairs to train the model via SimPO to dynamically adjust reasoning length
Architecture
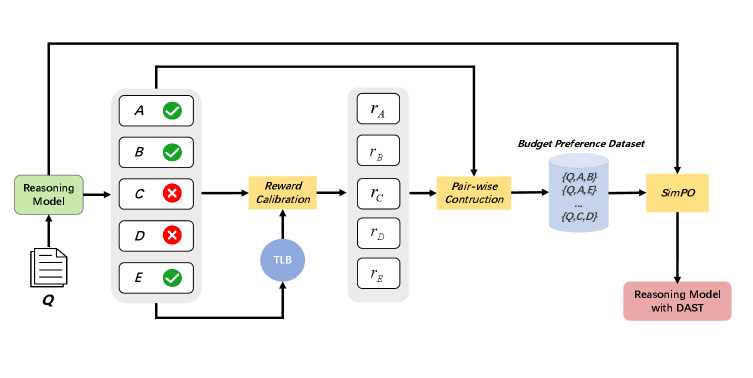
The overall framework of DAST, illustrating the process from difficulty quantification to model training.
Evaluation Highlights
- +10.0% accuracy improvement on the challenging AIME 2024 benchmark for DeepSeek-R1-Distill-Qwen-7B compared to the original model, while maintaining efficiency
- Reduces token usage by 58.5% on simple MATH-500 Level 1 problems vs. only 40.8% on Level 5, demonstrating true adaptive reasoning capability
- Achieves ~48% compression ratio on MATH-500 with DeepSeek-R1-Distill-Qwen-32B without compromising accuracy (96.0% vs 96.0%)
Breakthrough Assessment
8/10
Significantly improves upon 'one-size-fits-all' length penalties by successfully correlating reasoning length with difficulty. The ability to improve accuracy on hard tasks while compressing simple ones is a strong differentiator.