📝 Paper Summary
Reinforcement Learning with Verifiable Reward (RLVR)
Mathematical Reasoning
Data Efficiency in RLHF
Reinforcement learning with verifiable rewards using just a single mathematical training example significantly enhances the reasoning capabilities of large language models, generalizing well beyond the specific example or its format.
Core Problem
Current RLVR methods often rely on large datasets (thousands of examples), and the minimum data requirements for effective reasoning alignment remain unexplored.
Why it matters:
- Data-centric aspects of RLVR are underexplored compared to algorithmic refinements.
- Understanding minimal data requirements reveals intrinsic reasoning capabilities of base models.
- Reducing training data size could drastically lower computational costs for alignment.
Concrete Example:
A base model like Qwen2.5-Math-1.5B scores only 36.0% on MATH500. Standard approaches use thousands of examples (e.g., DeepScaleR uses 1.2k) to improve this, assuming large-scale data is necessary for generalization, whereas this paper shows one example suffices.
Key Novelty
1-shot RLVR (One-Shot Reinforcement Learning with Verifiable Reward)
- Train an LLM using RL (GRPO) on a single mathematical problem repeatedly.
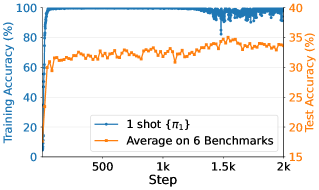
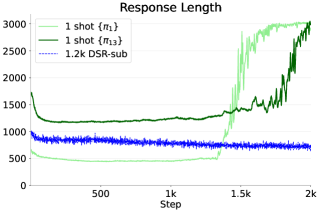
- Demonstrates 'post-saturation generalization': test accuracy continues to improve even after training accuracy saturates and the model overfits the single example into gibberish.
- Shows that policy gradient loss drives improvement rather than 'grokking' regularization, and cross-category generalization occurs from just one example.
Architecture
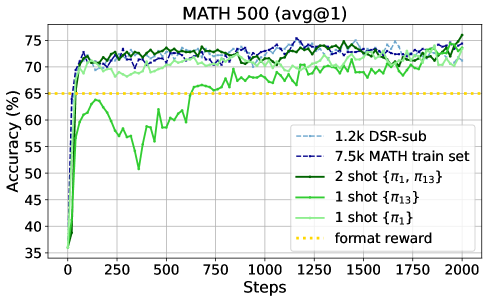
Performance comparison of 1-shot RLVR vs. Format Reward baseline vs. Full Dataset RLVR on MATH500 and Average benchmarks.
Evaluation Highlights
- +37.6% accuracy on MATH500 (36.0% → 73.6%) using Qwen2.5-Math-1.5B trained on a SINGLE example.
- Outperforms the 1.2k DeepScaleR subset baseline on average across 6 benchmarks (35.7% vs 35.9%) using just one example.
- Achieves 74.8% on MATH500 with just TWO training examples, slightly exceeding the 1.2k dataset result.
Breakthrough Assessment
9/10
Extremely surprising finding that challenges fundamental assumptions about data scale in RL alignment. Demonstrates that one example can unlock latent reasoning capabilities across diverse tasks.