📝 Paper Summary
Self-evolving Agentic reasoning
Reinforcement Learning with Verifiable Rewards (RLVR)
Code Generation
Absolute Zero Reasoner (AZR) enables LLMs to improve reasoning capabilities without human data by playing a dual role of task proposer and solver within a verified coding environment.
Core Problem
Current reasoning models rely on large-scale, human-curated datasets of questions and answers, which are becoming unsustainable to scale and may limit AI to human-level intelligence.
Why it matters:
- Dependence on expert-curated data creates a scalability bottleneck similar to the one identified in LLM pretraining
- Exclusive reliance on human-designed tasks restricts the capacity for autonomous AI learning and growth beyond human intellect
- Existing self-play methods are often limited to narrow domains (like games) or rely on neural reward models prone to reward hacking
Concrete Example:
In standard RLVR, a model needs a dataset of math problems and answers (e.g., from GSM8K) to learn. If the dataset runs out or lacks diversity, the model stops improving. AZR, conversely, autonomously generates a code induction task (e.g., 'write a function that transforms input A to output B') and learns by solving it.
Key Novelty
Absolute Zero (AZ) Paradigm
- A single language model acts as both 'Proposer' (creating tasks) and 'Solver' (solving them), learning from the interaction without external data
- Uses code execution as a grounded environment to verify three types of reasoning tasks: Deduction (output prediction), Abduction (input inference), and Induction (program synthesis)
- The Proposer is rewarded for 'learnability' (tasks that are solvable but not trivial), while the Solver is rewarded for correctness, creating an auto-curriculum
Architecture
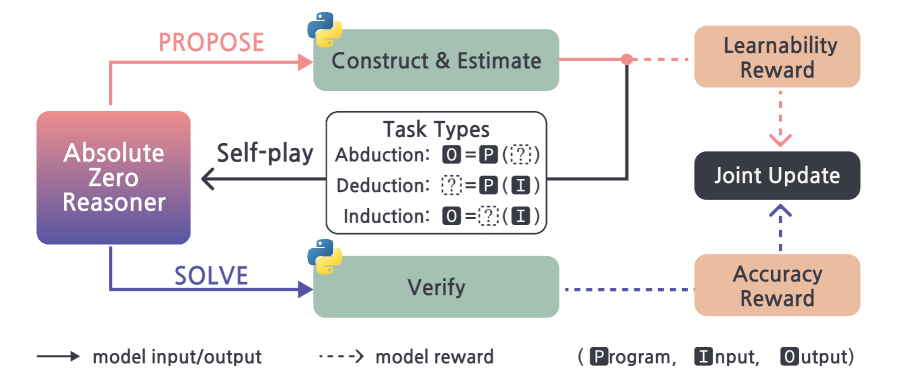
The Absolute Zero Reasoner (AZR) self-play loop
Evaluation Highlights
- AZR-Coder-7B improves average math performance by +15.2 points over the base model without seeing any math data
- Performance gains scale with model size: 3B, 7B, and 14B coder models gain +5.7, +10.2, and +13.2 points respectively
- Outperforms previous 'zero' setting models (trained on in-domain data) by an average of 1.8 absolute points
Breakthrough Assessment
8/10
Proposes a viable path for open-ended self-improvement without human data, demonstrating that general reasoning (math) can emerge purely from self-proposed coding tasks.

