📝 Paper Summary
Large Reasoning Models (LRMs)
Reasoning evaluation
Chain-of-Thought (CoT)
Reasoning models exhibit a complexity-dependent scaling limit where accuracy collapses and thinking effort paradoxically decreases beyond a certain complexity threshold, challenging claims of generalizable reasoning.
Core Problem
Current evaluations of Large Reasoning Models (LRMs) rely on static math benchmarks susceptible to data contamination and fail to systematically probe how reasoning capabilities and internal thought processes scale with problem complexity.
Why it matters:
- Established benchmarks like MATH do not allow controlled manipulation of complexity, masking whether models truly reason or rely on pattern matching
- Understanding the scaling limits of reasoning is crucial for determining if current RL-based 'thinking' paradigms can achieve general intelligence or if they hit hard ceilings
- Data contamination in popular benchmarks makes it difficult to distinguish genuine reasoning improvements from memorization
Concrete Example:
In a Tower of Hanoi puzzle, as the number of disks increases, an LRM might solve the 3-disk version perfectly but fail completely on the 6-disk version. Critically, for the complex failing case, the model paradoxically generates *fewer* thinking tokens than for medium-complexity cases, essentially 'giving up' rather than thinking harder.
Key Novelty
Controllable Puzzle-Based Reasoning Stress-Test
- Replaces static math benchmarks with four algorithmic puzzle environments (e.g., Tower of Hanoi, River Crossing) where complexity is a tunable parameter (N disks, N agents)
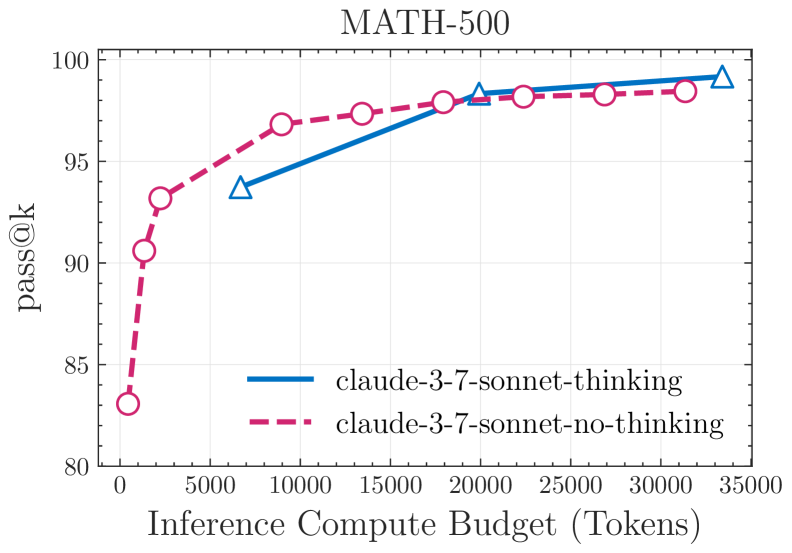
- Systematically compares 'thinking' models (LRMs) against their 'non-thinking' standard counterparts under equal inference compute budgets to isolate the benefit of reasoning tokens
- Analyzes internal 'thought' traces to reveal a 'collapse' phenomenon where models fixate on early errors and reduce thinking effort when complexity exceeds a threshold
Architecture
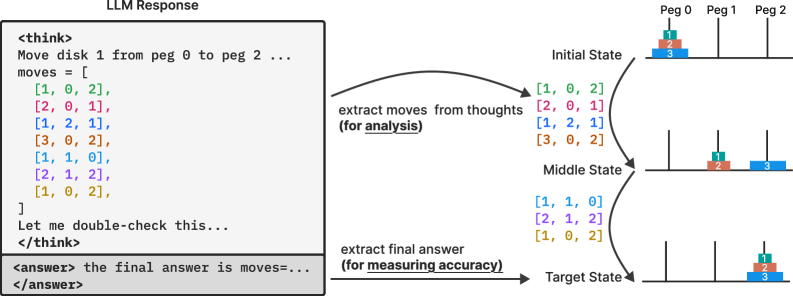
Conceptual flow of the experimental setup using controllable puzzle environments.
Evaluation Highlights
- Identified three performance regimes: non-thinking models are more efficient at low complexity; thinking models excel at medium complexity; both collapse to near-zero accuracy at high complexity
- Discovered a counterintuitive scaling limit: reasoning effort (thinking tokens) increases with complexity only up to a point, then decreases despite available token budget
- Reasoning models like DeepSeek-R1 and Claude-3.7-Sonnet-Thinking fail to use explicit algorithms, showing inconsistent reasoning across scales
Breakthrough Assessment
8/10
Strong empirical critique of the 'reasoning' narrative. By using controlled puzzles, it exposes fundamental scaling limitations and the 'giving up' phenomenon in frontier models that static benchmarks miss.