📝 Paper Summary
Large Reasoning Models (LRMs)
Reinforced Reasoning
This survey conceptualizes a roadmap for transitioning from Conversational AI to Large Reasoning Models by combining automated data synthesis, reinforcement learning, and test-time search strategies.
Core Problem
Standard LLMs trained on next-token prediction lack the ability to perform complex, multi-step logical reasoning (System 2 thinking), and human annotation for such reasoning trajectories is prohibitively expensive to scale.
Why it matters:
- A 'deficit of thought' limits LLMs from generalizing to complex real-world problems like coding, math, and autonomous agents.
- Relying solely on human annotation is unsustainable for the massive data volumes needed to supervise step-by-step reasoning.
- Existing scaling laws for model size (train-time) need to be augmented with test-time compute scaling to achieve AGI-level reasoning.
Concrete Example:
When solving a complex math problem, a standard LLM might try to guess the answer immediately (System 1). In contrast, a reasoning model needs to generate intermediate 'thought' tokens, verify them, and backtrack if necessary (System 2), but lacks the training data to learn this process effectively from human demonstrators.
Key Novelty
The 'Reinforced Reasoning' Paradigm
- Integrates 'Search' (generating reasoning trajectories via trial-and-error) and 'Learning' (training on those trajectories via RL) into a reinforced cycle.
- Shifts the supervision signal from sparse final answers to dense Process Reward Models (PRMs) that evaluate intermediate steps.
- Proposes scaling reasoning not just by model size, but by increasing 'thinking' tokens during inference (Test-time scaling).
Architecture
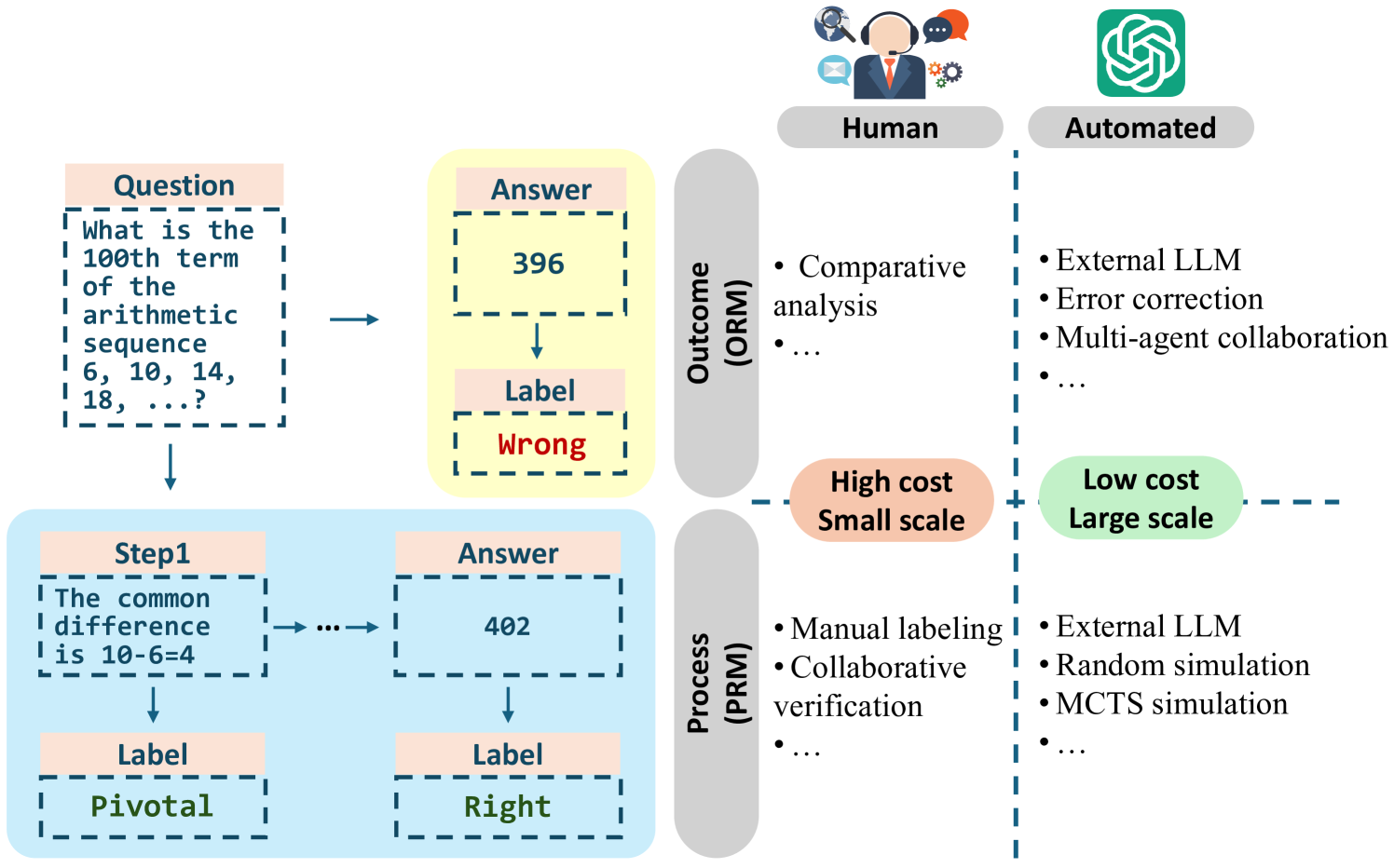
A comparison of data construction methods, contrasting Human Annotation with LLM Automation.
Breakthrough Assessment
8/10
Provides a timely and comprehensive taxonomy for the emerging field of Large Reasoning Models (like OpenAI o1), unifying data construction, RL, and search into a coherent roadmap.