📝 Paper Summary
Software Engineering (SE) for LLMs
Reasoning via Reinforcement Learning (RL)
SWE-RL improves LLM reasoning by applying reinforcement learning on open-source software evolution data (pull requests) with rule-based rewards, achieving state-of-the-art results on SWE-bench without proprietary distillation.
Core Problem
Current LLM approaches for software engineering rely heavily on proprietary models (GPT-4) or SFT, lacking the ability to self-improve reasoning through RL due to the high cost of execution-based rewards.
Why it matters:
- Proprietary models limit accessibility and transparency in software engineering research
- Existing open models struggle with complex real-world issue solving compared to closed models
- Standard RL approaches (like in math/comp-coding) rely on execution feedback which is costly or unavailable for partial repository contexts
Concrete Example:
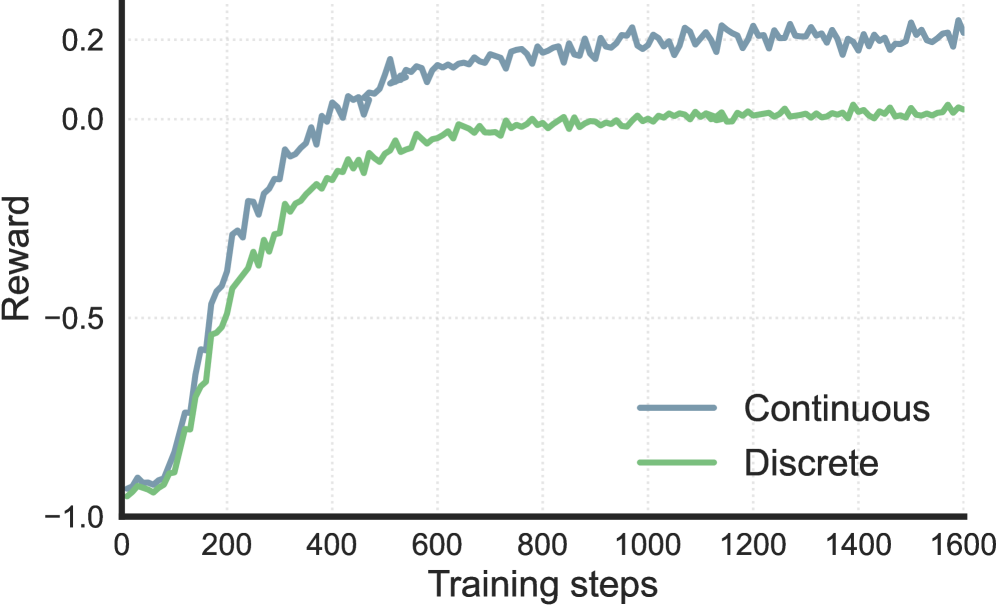
When given a GitHub issue, a standard Llama-3 model often fails to locate the bug or generates incorrect patch formats. In contrast, SWE-RL, trained on PR histories, learns to 'think' longer about fault locations and produces valid patches by maximizing similarity to ground-truth developer edits.
Key Novelty
SWE-RL (Reinforcement Learning on Software Evolution)
- Train an LLM using RL (GRPO) directly on historical Pull Request (PR) data, treating the developer's final patch as the ground truth oracle
- Use a lightweight rule-based reward (sequence similarity between predicted and oracle patch) instead of expensive execution feedback or binary correctness
- Include full file contents in the prompt to implicitly force the model to perform fault localization and reasoning before editing
Architecture
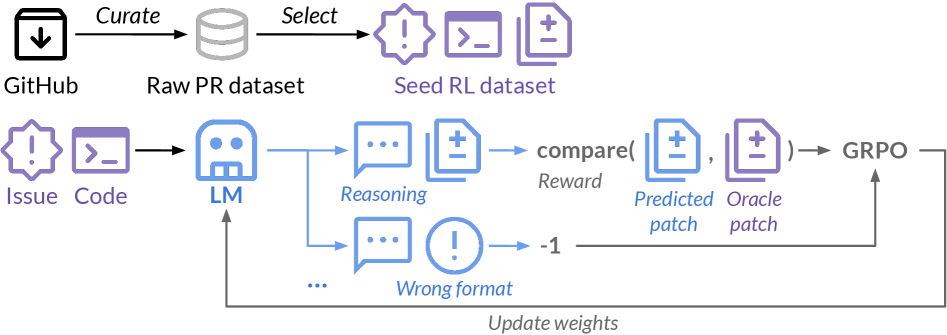
Overview of the SWE-RL framework: from PR data collection to RL training loop and final inference.
Evaluation Highlights
- Achieves 41.0% pass@1 on SWE-bench Verified, the best performance among open models <100B parameters and comparable to GPT-4o
- Demonstrates generalization: +6.3% on HumanEval+ and +4.2% on MBPP+ compared to the base model, despite training only on issue solving
- Surpasses supervised fine-tuning (SFT) baselines on both in-domain (SWE-bench) and out-of-domain tasks (MATH, CRUXEval)
Breakthrough Assessment
9/10
First successful application of RL solely on software evolution data to achieve SOTA reasoning. Demonstrates that RL on SE data generalizes to math/reasoning, a major finding parallel to DeepSeek-R1 but using open data.