📝 Paper Summary
Reasoning Segmentation
Multimodal Large Language Models (MLLMs)
Reinforcement Learning
Seg-Zero activates emergent pixel-level reasoning in MLLMs using pure reinforcement learning without explicit reasoning data, decoupling the reasoning process from the segmentation model.
Core Problem
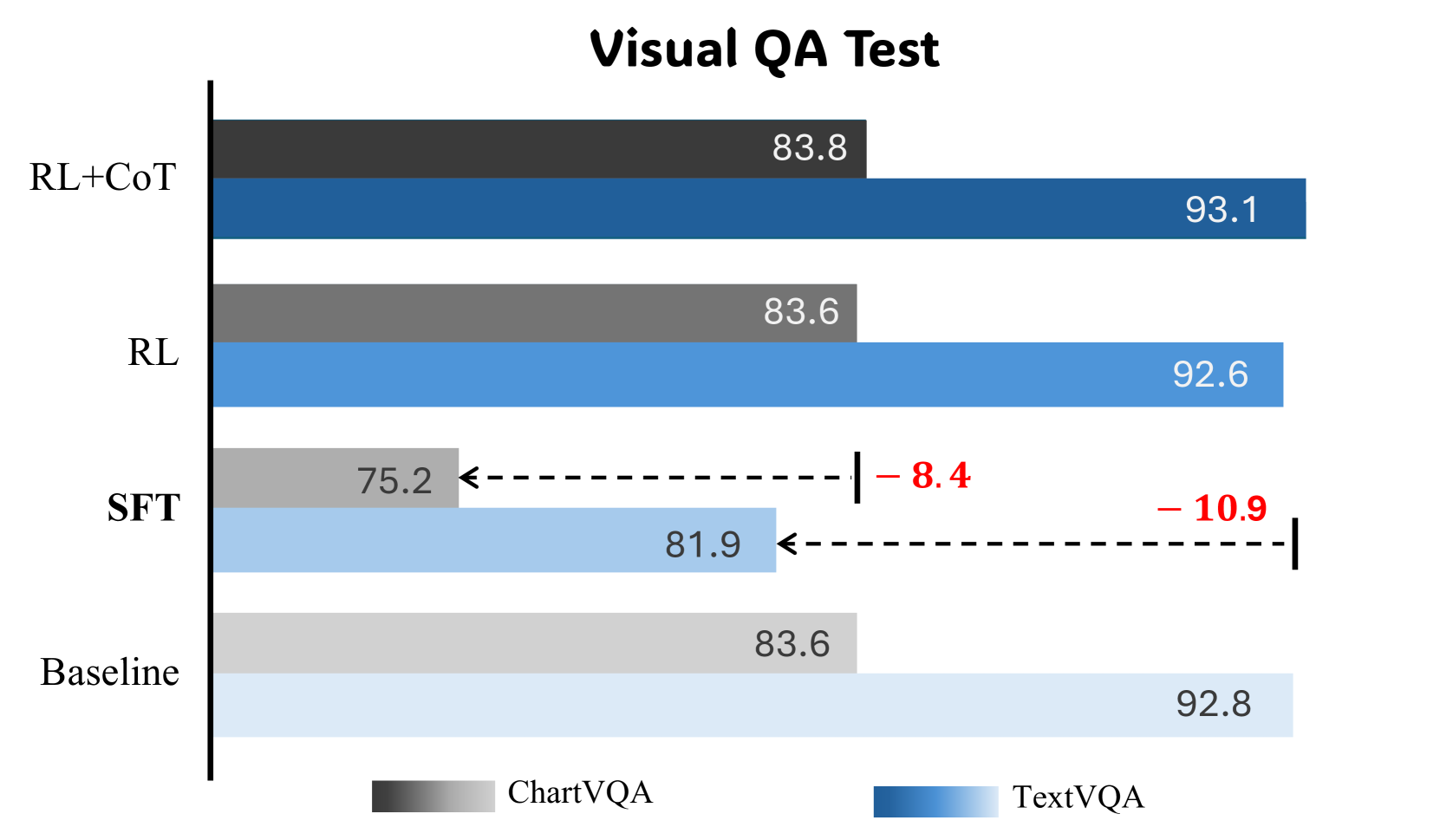
Current reasoning segmentation methods rely on supervised fine-tuning (SFT) with simple labels, leading to poor generalization on complex queries and catastrophic forgetting of general capabilities.
Why it matters:
- SFT limits models to in-domain data, causing significant performance degradation on out-of-distribution (OOD) samples
- Lack of explicit reasoning processes hinders effectiveness in complex scenarios requiring multi-step logic (e.g., 'food that provides sustained energy')
- Fine-tuning multimodal models on segmentation data often causes catastrophic forgetting of their original visual QA capabilities
Concrete Example:
When asked to 'identify food that provides sustained energy,' standard SFT models trained on simple labels like 'banana' fail to connect the functional description to the object, whereas a reasoning model breaks this down logically before segmenting.
Key Novelty
Seg-Zero: Pure RL-driven Emergent Reasoning for Segmentation
- Decouples reasoning (MLLM) from segmentation (SAM2), using the MLLM to generate reasoning chains, bounding boxes, and points which prompt the frozen segmentation model
- Trains the MLLM from scratch using pure Reinforcement Learning (GRPO) with outcome-based rewards (IoU, format) instead of supervised reasoning traces, allowing reasoning strategies to emerge naturally
Architecture
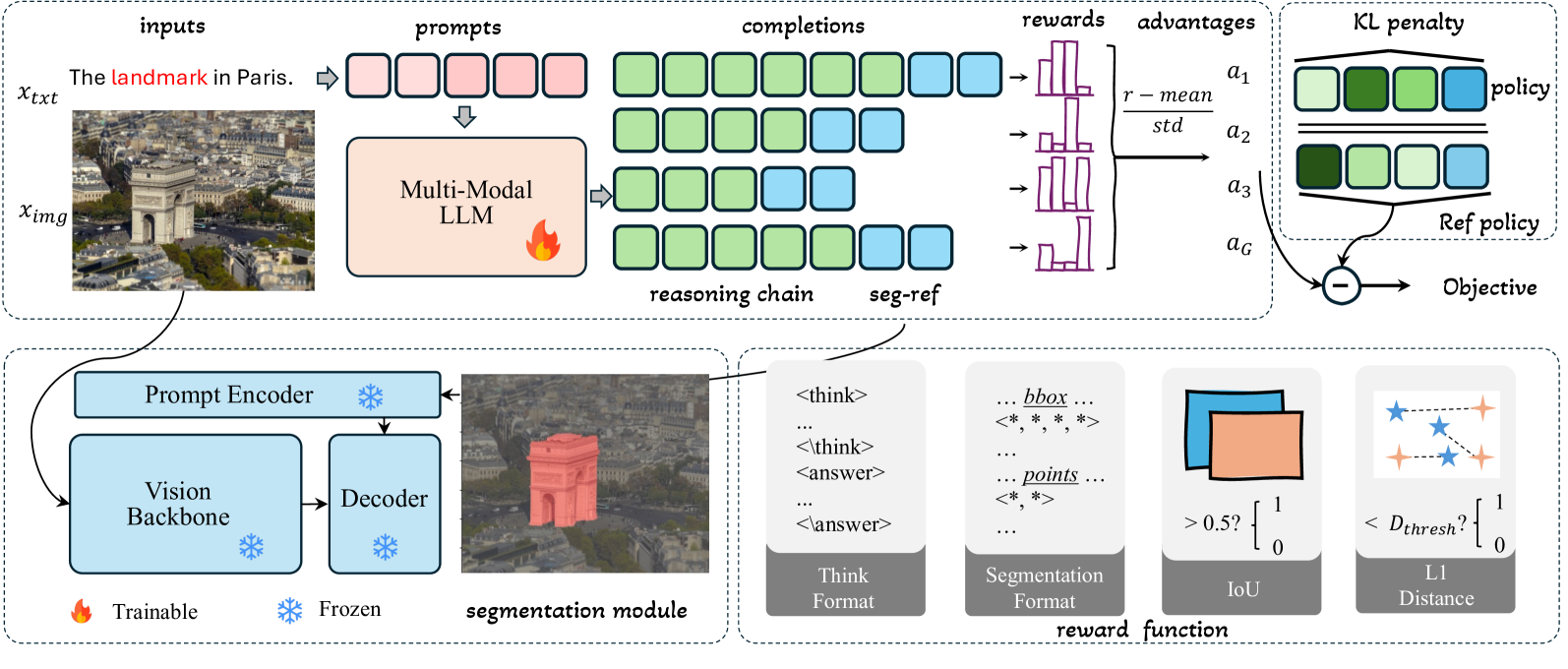
The Seg-Zero architecture illustrating the decoupled reasoning and segmentation process.
Evaluation Highlights
- Achieves 57.5 zero-shot performance on ReasonSeg benchmark, surpassing prior LISA-7B by 18%
- Trained with only 9,000 samples from RefCOCOg yet exhibits strong OOD generalization
- Preserves original Visual QA capabilities better than SFT baselines, which suffer catastrophic forgetting
Breakthrough Assessment
8/10
Significant advance in applying the 'reasoning-0' RL paradigm (like DeepSeek-R1) to vision tasks, showing emergent reasoning improves segmentation without expensive annotated reasoning data.