📊 Experiments & Results
Evaluation Setup
Mathematical reasoning evaluation using response-level selection and step-level error detection
Benchmarks:
- GSM8K (Grade school math)
- MATH (Challenging math problems)
- OlympiadBench (Olympiad-level math)
- ProcessBench (Step-wise error identification)
Metrics:
- Best-of-N Accuracy (prm@8)
- ProcessBench F1 Score (identifying first error step)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Results on ProcessBench (step-level evaluation) showing massive improvements in error detection capability. | ||||
| ProcessBench | Mean F1 | 31.5 | 73.5 | +42.0 |
| ProcessBench | Mean F1 | 61.9 | 73.5 | +11.6 |
| Results on Best-of-8 (response-level evaluation) across 7 math datasets. | ||||
| Average (7 datasets) | Best-of-8 Accuracy | 64.2 | 67.6 | +3.4 |
| MATH | Best-of-8 Accuracy | 85.4 | 88.0 | +2.6 |
| Ablation study on data synthesis methods (Best-of-8 Accuracy). | ||||
| Average (BoN) | Accuracy | 64.3 | 65.7 | +1.4 |
Experiment Figures
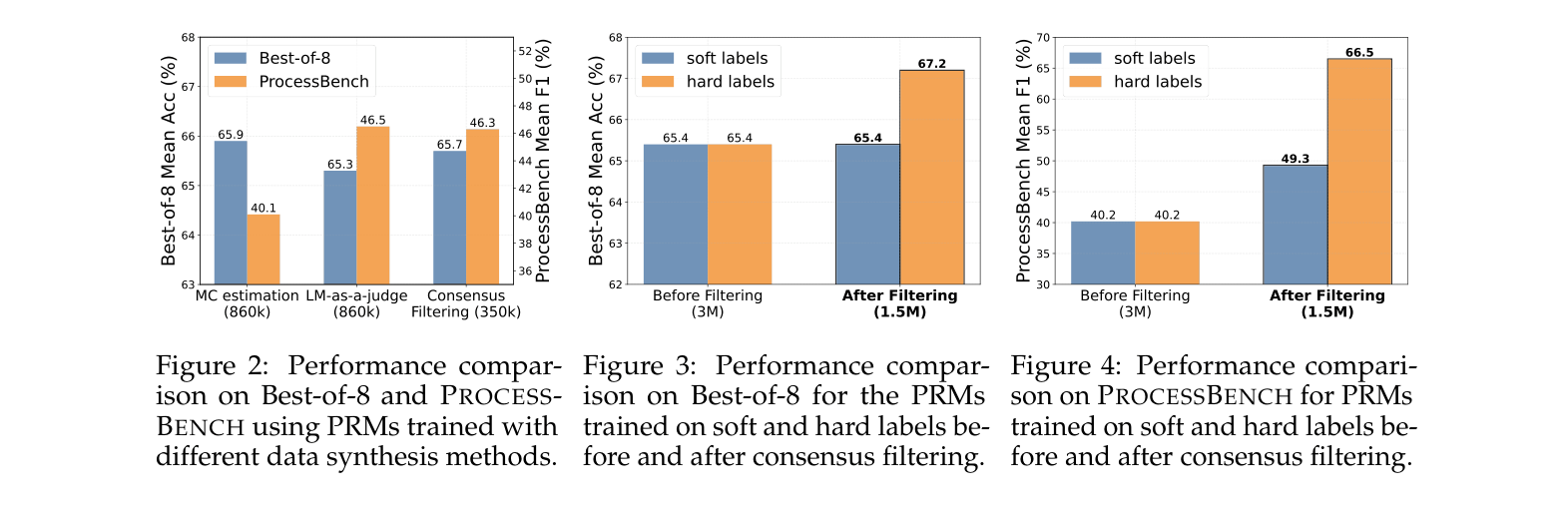
Comparison of data synthesis methods on BoN and ProcessBench performance
Main Takeaways
- Consensus filtering (MC + LLM agreement) creates much higher quality training data than MC alone, enabling a 7B model to outperform larger baselines
- Traditional MC-trained PRMs suffer from 'process-to-outcome shift', where minimum scores drift to the final step, effectively becoming ORMs
- Hard labels (0/1) derived from MC thresholds perform better than soft labels (probabilities) when using filtered data
- Evaluating PRMs solely on Best-of-N is misleading; models with high BoN scores can still fail catastrophically at identifying specific error steps (ProcessBench)