📝 Paper Summary
Mathematical Reasoning Datasets
Reinforcement Learning with Verifiable Rewards (RLVR)
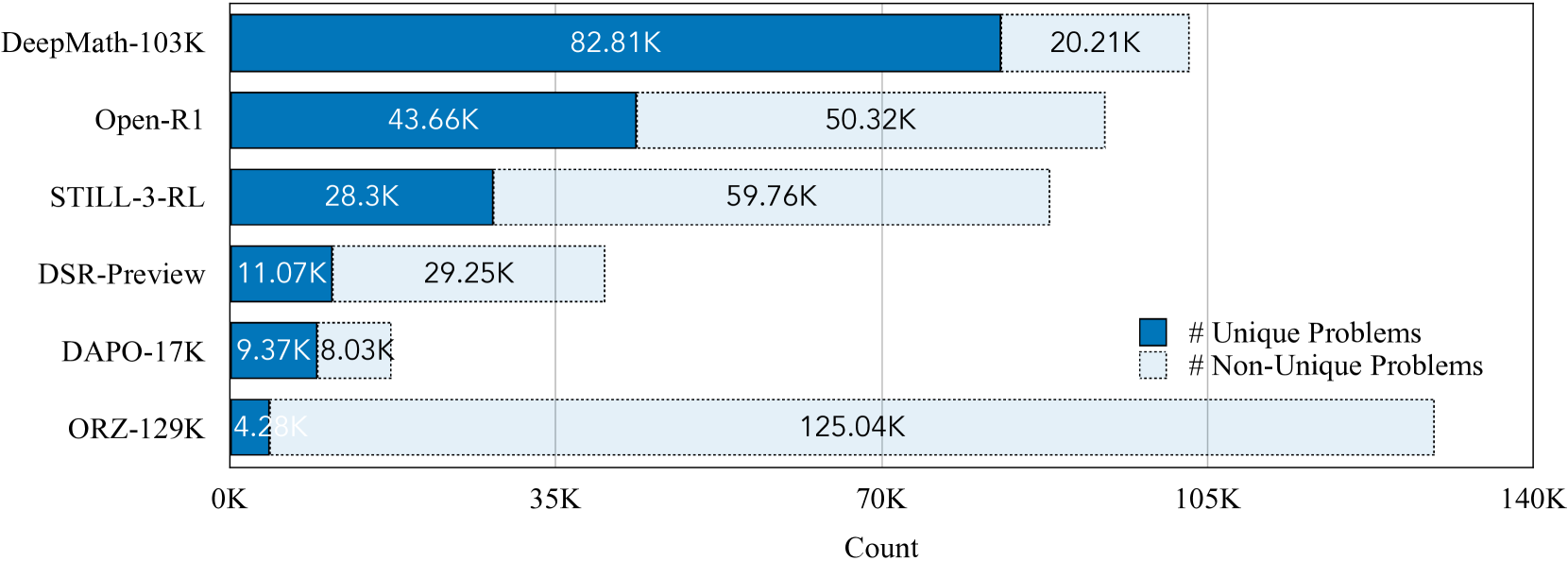
DeepMath-103K is a high-difficulty mathematical dataset constructed from informal forums, rigorously decontaminated, and formatted with verifiable answers to enable effective reinforcement learning for advanced reasoning.
Core Problem
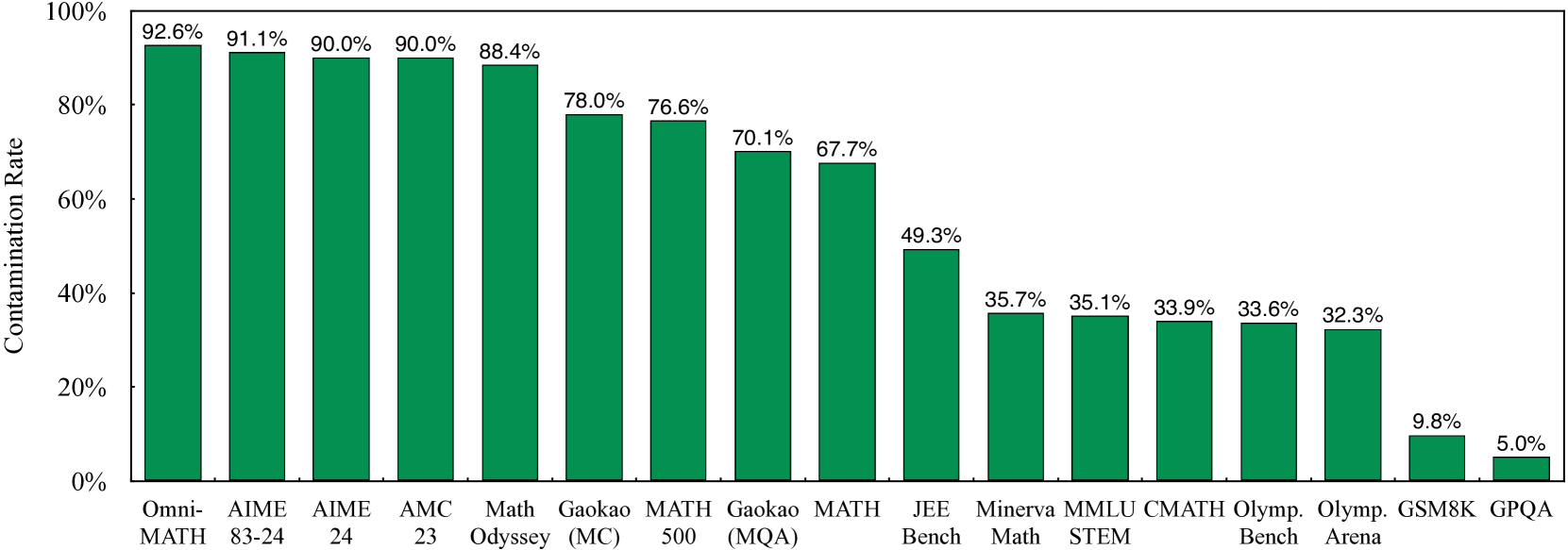
Existing mathematical datasets for RL often lack sufficient difficulty, suffer from high contamination with evaluation benchmarks (up to 90%), or lack verifiable answers needed for reliable reward signals.
Why it matters:
- Advanced models (like DeepSeek-R1) need increasingly harder problems to improve reasoning, but current open datasets are saturated with easy problems.
- High contamination rates in training data (e.g., AIME problems) make evaluation scores unreliable and inflate perceived progress.
- RL with Verifiable Rewards (RLVR) requires unambiguous final answers to prevent reward hacking, which many open-ended datasets lack.
Concrete Example:
A raw problem from Math StackExchange might be a conversational forum post without a clear question or answer format. DeepMath-103K transforms this into a structured query with a verifiable symbolic answer, whereas standard scraping might leave it unusable for rule-based RL.
Key Novelty
DeepMath-103K Dataset Construction Pipeline
- Sources data primarily from informal math forums (Math StackExchange) rather than recycling common competition sets like AIME, ensuring high novelty.
- Implements a rigorous semantic decontamination process to remove problems similar to 14 major benchmarks, ensuring evaluation integrity.
- Enforces 'verifiability' by filtering for problems where rule-based extractors recover consistent answers across multiple DeepSeek-R1 solution paths.
Architecture
The data curation pipeline for creating DeepMath-103K.
Evaluation Highlights
- DeepMath-Omn-1.5B achieves 64.0% pass@1 on AIME24, surpassing o1-mini (63.6%) and o3-mini-low (60.0%).
- DeepMath-Zero-7B improves pass@1 on AIME24 by +12.7% (from 42.9% to 55.6%) over the base Qwen-2.5-Math-7B model.
- DeepMath-1.5B (initialized from R1-Distill) improves pass@1 on AIME25 by +6.0% (from 43.1% to 49.1%) after training.
Breakthrough Assessment
9/10
Provides a critical, high-quality resource (challenging, decontaminated, verifiable data) that directly addresses the bottleneck in open-source reasoning model development. Significant performance gains over strong baselines.