📝 Paper Summary
RL for LLMs
Large Reasoning Models (LRMs)
Distributed Training Systems
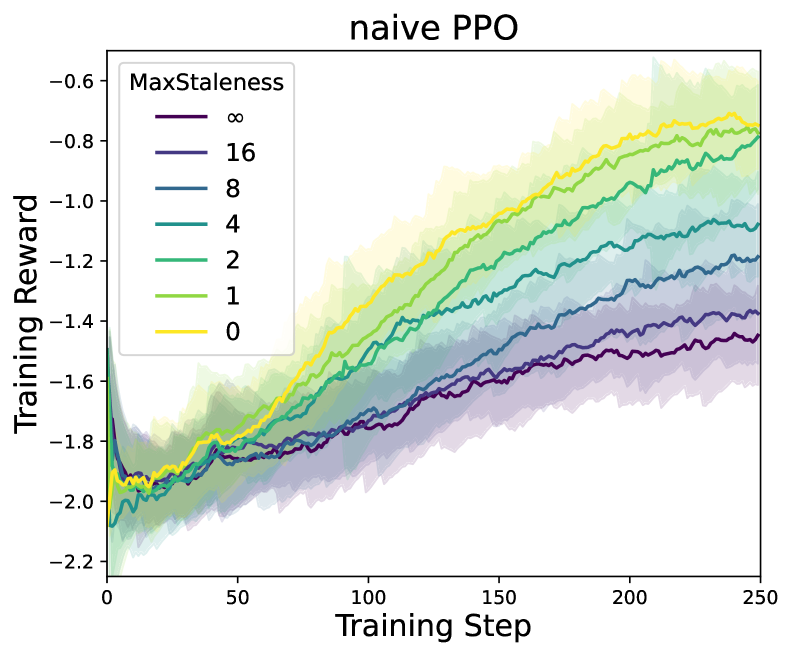
AReaL is a fully asynchronous RL system for large reasoning models that decouples generation from training to maximize GPU utilization, using a staleness-aware PPO algorithm to handle off-policy data.
Core Problem
Synchronous RL systems for LLMs suffer from severe GPU underutilization because the generation phase must wait for the longest sequence in a batch to finish before training can proceed.
Why it matters:
- Thinking LLMs (Large Reasoning Models) have highly variable output lengths (up to tens of thousands of tokens), causing significant idle time in synchronous systems
- Batch generation in synchronous systems forces decoding into memory-IO-bound regimes, limiting scalability
- Current approaches that overlap generation and training often restrict data staleness to just one or two steps, still enforcing batched generation bottlenecks
Concrete Example:
In a synchronous setup, if one prompt generates a 500-token reasoning chain and another generates 10,000 tokens, the GPUs processing the short chain sit idle for most of the time waiting for the long chain to finish before model updates can occur.
Key Novelty
Fully Asynchronous RL with Interruptible Rollouts
- Decouples generation (rollout) and training into separate worker pools that run continuously without waiting for each other, treating generation as a streaming process
- Introduces 'interruptible rollout workers' that can stop generating mid-stream to update model weights and recompute KV caches, ensuring newer policies are used sooner
- Uses a decoupled PPO objective that treats the policy used for sampling (behavior policy) separately from the anchor for regularization (proximal policy), allowing stable training on stale data
Architecture
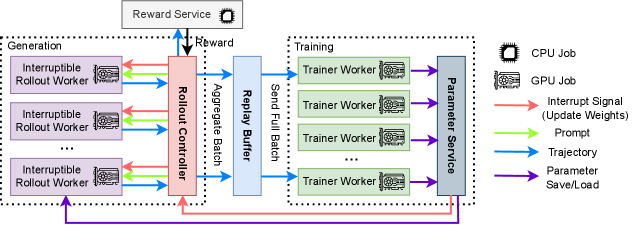
The system architecture of AReaL, showing the separation of duties between Rollout Workers and Trainer Workers.
Evaluation Highlights
- Achieves up to 2.77x training speedup compared to synchronous systems (ReaL) with the same number of GPUs
- Demonstrates linear scaling efficiency up to 512 GPUs
- Maintains or improves final model accuracy (e.g., +2.2% pass@1 on GSM8K with Llama-3-8B) despite using stale data
Breakthrough Assessment
9/10
Solving the 'straggler problem' in RL for reasoning models (where output lengths vary wildly) is a critical system bottleneck. Achieving nearly 3x speedup while preserving algorithmic stability is a major contribution.