📝 Paper Summary
Test-time compute scaling
Latent reasoning
Recurrent neural networks
A transformer architecture that scales test-time compute by iterating a recurrent block in latent space rather than generating more tokens, enabling performance gains on reasoning tasks without long chain-of-thought outputs.
Core Problem
Mainstream reasoning models scale test-time compute by generating long chains of thought, which wastes tokens on intermediate verbalization and requires specialized training data.
Why it matters:
- Verbalizing every intermediate thought is inefficient compared to human-like non-verbal reasoning
- Standard chain-of-thought approaches require massive context windows and specialized long-context training data
- Latent reasoning could capture abstract concepts (spatial, physical intuition) that are difficult to represent in words
Concrete Example:
When solving a complex math problem, a standard model must write out every step token-by-token. This requires a huge context window. The proposed model 'thinks' by looping its internal state 32 times before generating a single answer token, using the same small context window.
Key Novelty
Latent Recurrent Depth Transformer
- Instead of a fixed number of layers, the model has a 'core' block that loops a variable number of times (recurrent depth) during a single forward pass
- The model is trained with a randomized number of iterations per sample, allowing it to learn to think for longer or shorter periods
- Input embeddings are injected at every step of the loop to stabilize the recurrence (preventing the state from forgetting the prompt)
Architecture
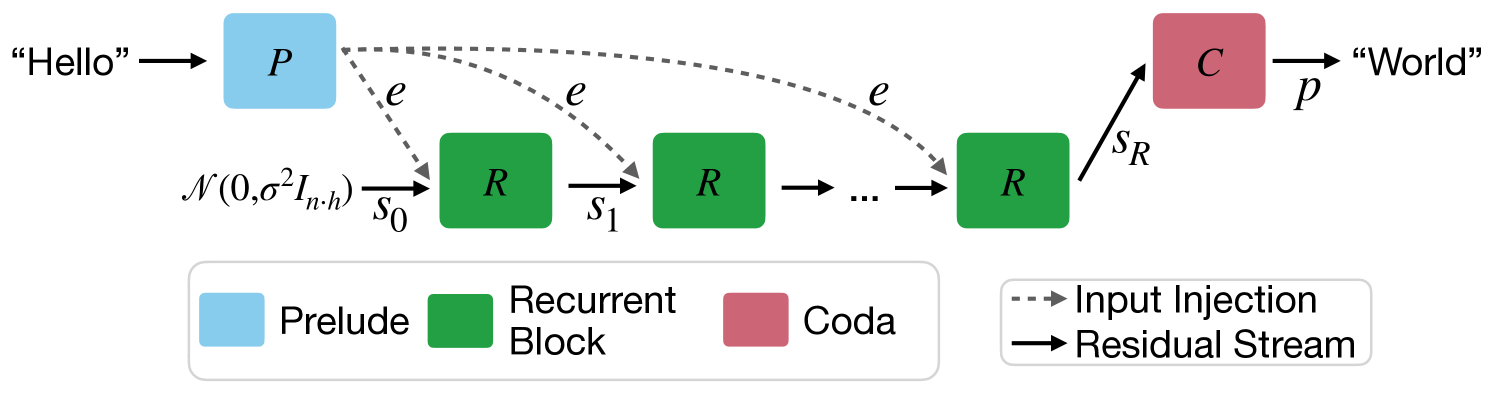
Diagram of the Recurrent Depth Architecture
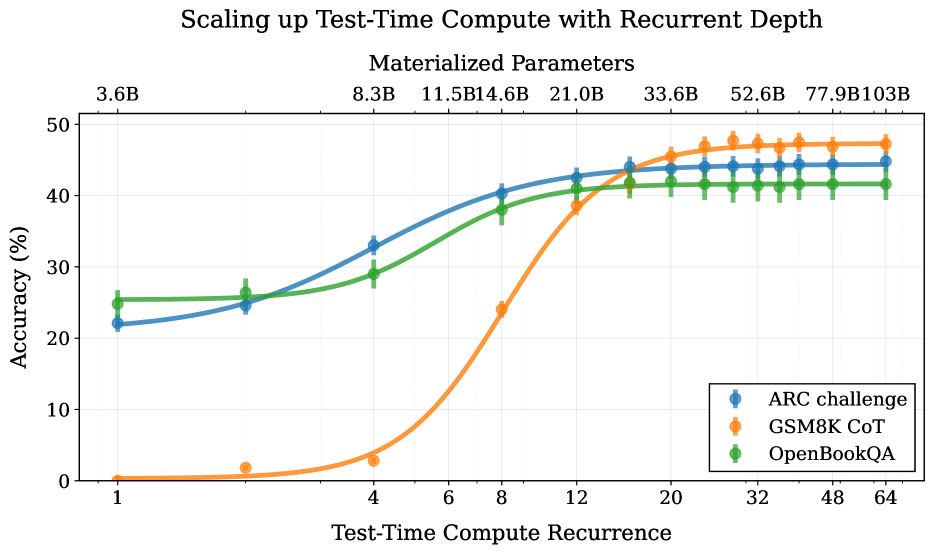
Evaluation Highlights
- The 2B parameter recurrent model matches the performance of a 9B parameter standard model (Gemma-2-9B) on math reasoning tasks when allowed to 'think' for 48 iterations
- Scaling inference iterations from 16 to 48 improves accuracy on the GSM8K benchmark from ~35% to ~45% without retraining
- Outperforms standard depth-scaled transformers (132 effective layers) while using significantly fewer parameters (3.5B params)
Breakthrough Assessment
8/10
Offers a compelling alternative to Chain-of-Thought for test-time scaling. The ability to decouple parameter count from effective depth and compute is a significant architectural shift.