📝 Paper Summary
Mathematical Reasoning
Small Language Models (SLMs)
Synthetic Data Generation
rStar-Math enables small language models to match OpenAI o1's math performance by iteratively generating high-quality, code-verified training data through MCTS and training a robust process preference model from scratch.
Core Problem
Small language models struggle with complex math reasoning because high-quality step-by-step training data is scarce, and existing distillation methods inherit the limitations of teacher models.
Why it matters:
- Distilling from larger models (like GPT-4) has diminishing returns and cannot help models surpass the teacher's capability
- Standard Chain-of-Thought generation often contains subtle logic errors in intermediate steps even if the final answer is correct, degrading training quality
- Training process reward models is difficult because precise step-level human annotation is expensive and automatic scoring is inherently noisy
Concrete Example:
In a complex math problem, an LLM might hallucinate a formula step but arrive at the correct answer by chance. Standard training would treat this entire trajectory as 'correct', reinforcing the hallucination. rStar-Math uses code execution to verify each step and MCTS rollouts to identify that this specific step rarely leads to success, filtering it out.
Key Novelty
Self-Evolved Deep Thinking via Code-Augmented MCTS
- Code-Augmented MCTS: Generates reasoning steps interleaved with Python code; only steps with successfully executing code are retained, filtering out hallucinations before reward scoring
- Process Preference Model (PPM): Replaces noisy absolute scoring of steps with a pairwise ranking approach, learning to prefer steps that lead to correct MCTS outcomes over those that do not
- Self-Evolution Recipe: A 4-round iterative loop where the policy and reward models generate their own improved training data to progressively tackle harder problems without external distillation
Architecture
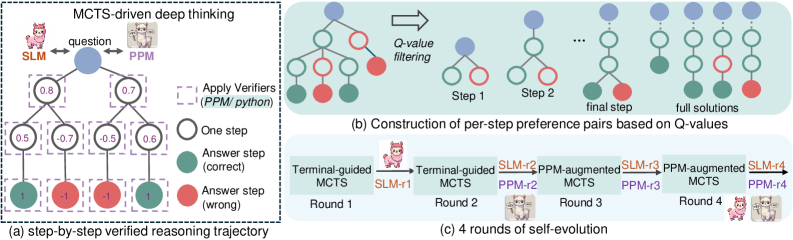
The 4-round self-evolution pipeline of rStar-Math. It illustrates the cycle of MCTS data generation, trajectory selection via Q-values, and training of the Policy SLM and PPM.
Evaluation Highlights
- Improves Qwen2.5-Math-7B from 58.8% to 90.0% on the MATH benchmark (pass@1 with 64 searches), surpassing o1-preview (85.5%)
- Solves 53.3% (8/15) of problems on the Olympiad-level AIME 2024 benchmark, outperforming o1-preview (46.7%) and base Qwen2.5-Math-7B (13.3%)
- Boosts smaller models significantly: Qwen2.5-Math-1.5B improves from 51.2% to 87.8% on MATH with 64 search trajectories
Breakthrough Assessment
9/10
Achieves SOTA math reasoning on small 7B models, surpassing o1-preview without distillation. The self-evolution recipe and PPM formulation offer a reproducible path for SLM scaling.
