📝 Paper Summary
Training Data Membership
Memorization in LLMs
Adversarial Data Construction
LLMs can verbatim complete text sequences even when those sequences are removed from training data based on n-gram overlap, revealing that current membership definitions are easily gamed.
Core Problem
Standard definitions of training data membership rely on n-gram overlap, assuming that if a model completes a text verbatim, that text must be in the training set.
Why it matters:
- Privacy and copyright auditing rely on checking if a model can reproduce text to determine if it was trained on it
- Unlearning methods often assume that removing specific n-grams is sufficient to prevent output generation, which this paper disproves
- Malicious actors could poison models or evade contamination detection by transforming text so it has no n-gram overlap but is still reconstructible
Concrete Example:
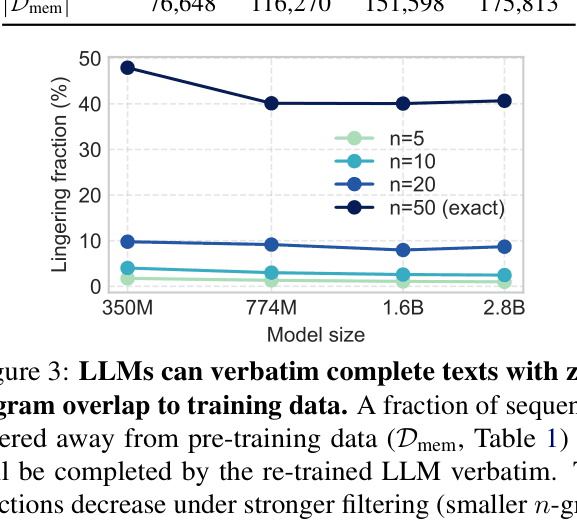
A model retrained from scratch after removing all 50-grams of a specific text (e.g., a famous quote) can still complete it verbatim because it learns from shorter overlaps or near-duplicates (e.g., '1477 by topic' matches '1477 by Topic').
Key Novelty
Gaming n-gram Membership via Auxiliary Information
- Demonstrates that removing exact n-gram matches from training data does not stop models from generating the removed text (lingering sequences)
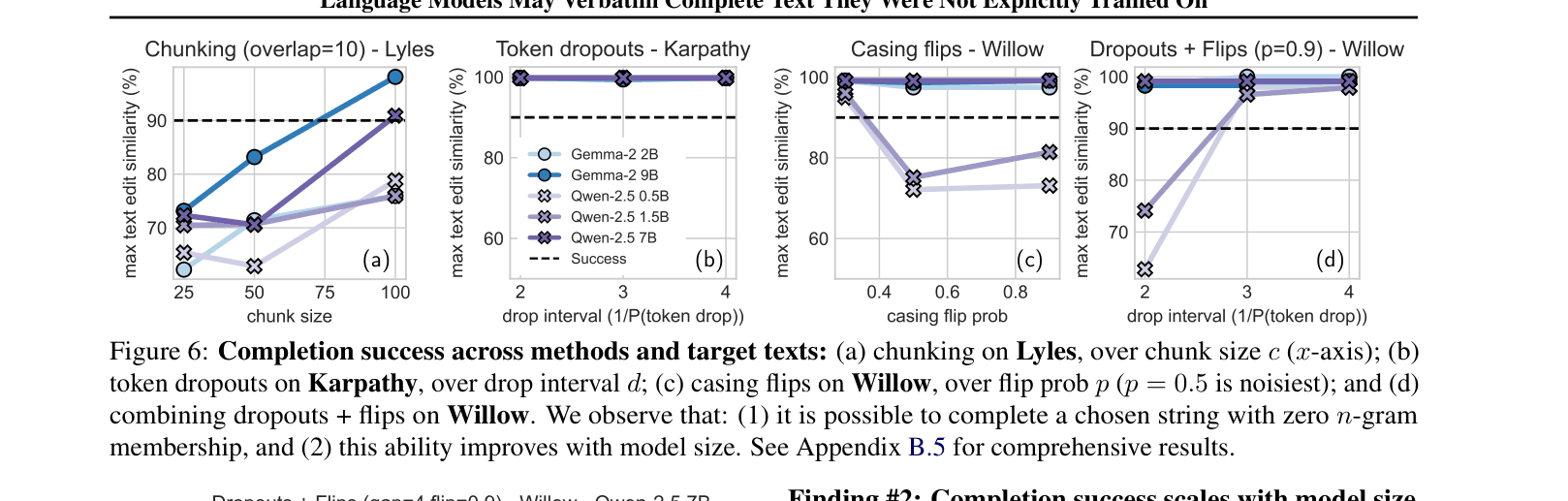
- Shows that adversarial datasets (using token dropouts or casing flips) can force a model to learn a target text without containing any valid n-grams of that text
Architecture
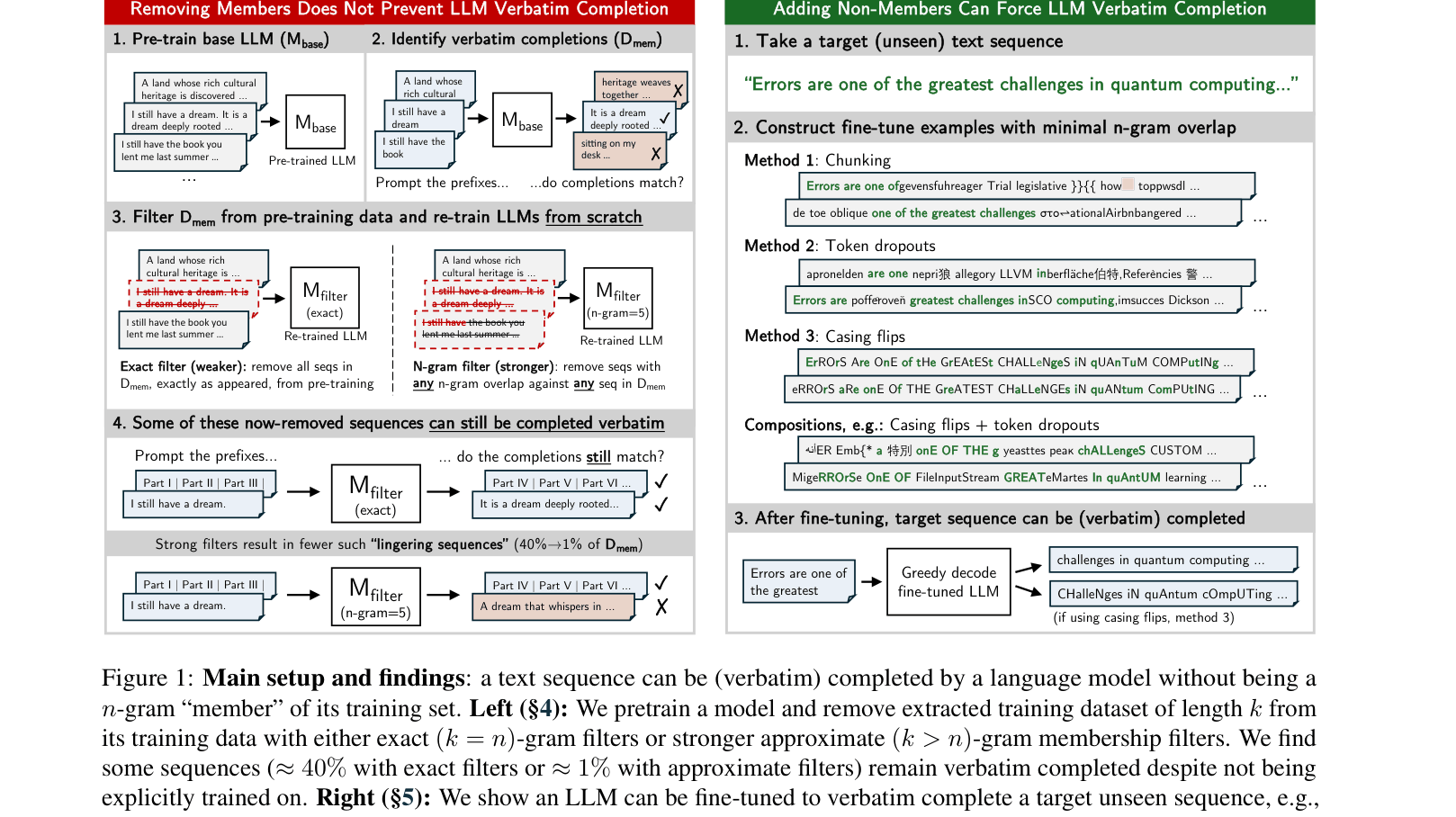
Overview of the two main experimental pipelines: (Left) Retraining with filters to find lingering sequences, and (Right) Adversarial fine-tuning to force completion without membership.
Evaluation Highlights
- Retrained 1.6B model verbatim completes ~40% of sequences that were explicitly removed using exact n-gram filtering
- Even with aggressive filtering (removing any text sharing a 5-gram), ~1% of removed sequences remain verbatim completable
- Adversarial token dropout (50% drop rate) allows a 0.5B model to learn and verbatim complete a target text despite zero n-gram overlap in training
Breakthrough Assessment
8/10
Fundamentally challenges the standard operational definition of 'membership' used in privacy and copyright, showing it is insufficient and easily circumvented.