📝 Paper Summary
Reasoning Language Models
Test-time Compute Scaling
Reinforcement Learning
Length Controlled Policy Optimization (LCPO) trains reasoning models to strictly adhere to user-specified chain-of-thought length constraints while maximizing accuracy, enabling precise control over test-time compute.
Core Problem
Current reasoning models (like O1, R1) generate variable-length chains-of-thought without user control, making it impossible to allocate specific test-time compute budgets or prevent wasteful overthinking.
Why it matters:
- Uncontrolled models may generate tens of thousands of tokens unnecessarily, wasting substantial compute resources.
- Existing solutions like 'budget-forcing' (S1) simply truncate generation or insert stop tokens, which interrupts reasoning and severely degrades performance.
- Users cannot currently calibrate inference costs vs. accuracy for real-time applications where latency or cost ceilings are critical.
Concrete Example:
When an S1 model reaches its token limit, it inserts a 'Final Answer' token, often forcing the model to guess before solving the problem. In contrast, L1 adapts its strategy to solve the problem within the requested 512 tokens.
Key Novelty
Length Controlled Policy Optimization (LCPO)
- Condition the model on a specific target length (e.g., <512 tokens>) explicitly in the prompt during both training and inference.
- Train using Reinforcement Learning (GRPO) with a reward function that penalizes deviations from the target length while rewarding correct answers.
- This incentivizes the model to learn how to compress or expand its reasoning steps dynamically to fit the budget, rather than just truncating output.
Architecture
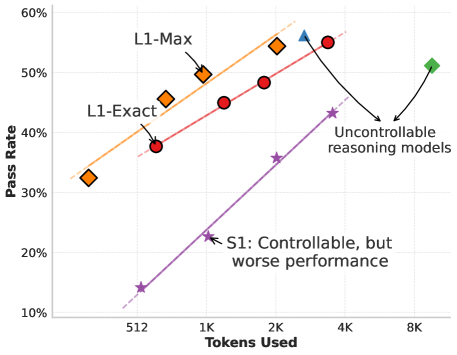
Conceptual comparison of standard reasoning (uncontrolled), S1 (truncated/forced), and L1 (adaptive length control).
Evaluation Highlights
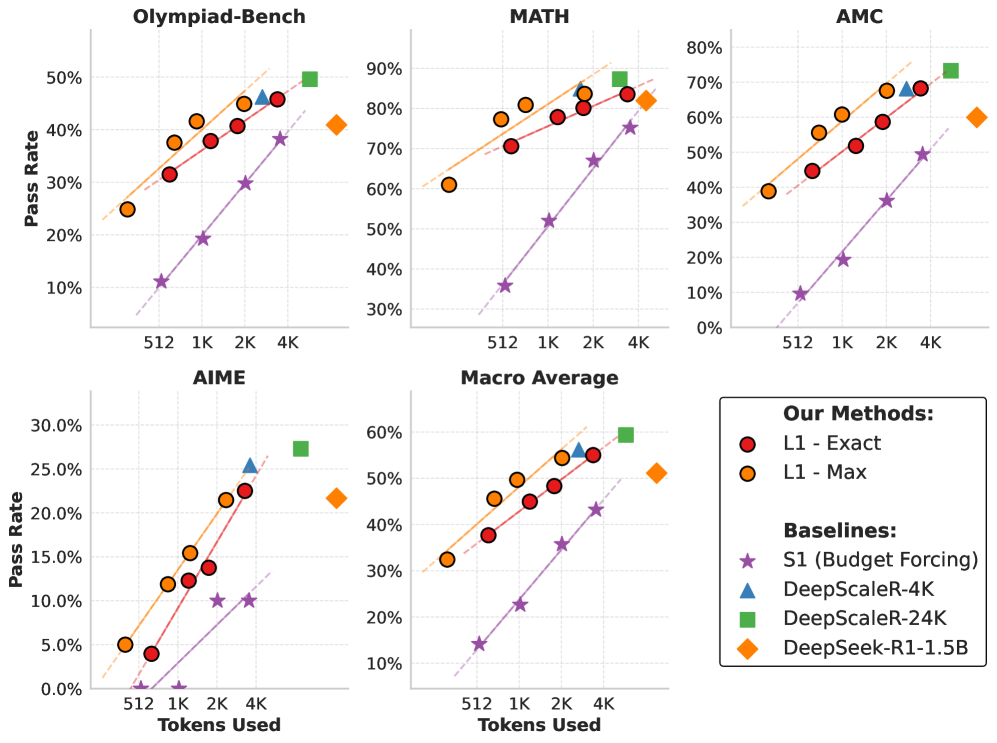
- +100% relative performance gain over S1 (state-of-the-art budget forcing) on math reasoning tasks at low token budgets (512/1024 tokens).
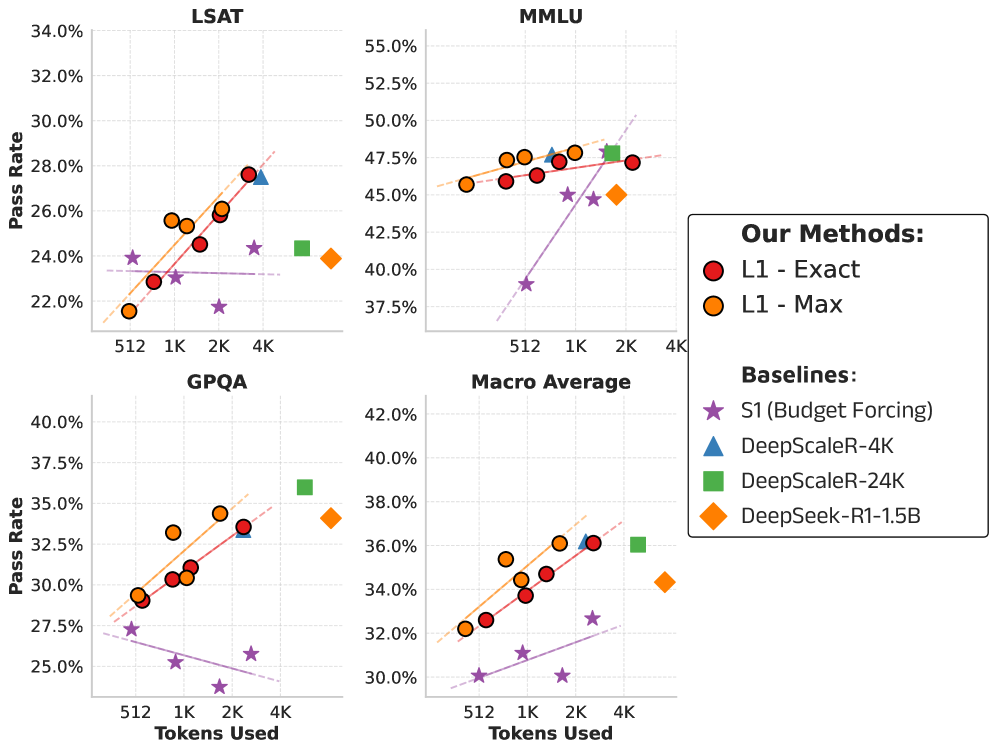
- Outperforms GPT-4o by 2% on average across reasoning benchmarks when restricted to the same generation length, despite being a much smaller 1.5B parameter model.
- Achieves ~3% mean error in length adherence across math reasoning datasets, demonstrating high precision in following length constraints.
Breakthrough Assessment
9/10
Solves a critical, unaddressed problem in reasoning models (uncontrollable compute) with a simple, effective RL solution. The result—a 1.5B model beating GPT-4o at equal lengths—is highly significant.