📝 Paper Summary
Multimodal Reasoning
Tool-use for VLMs
Reinforcement Learning for VLMs
Pixel Reasoner empowers VLMs to actively manipulate visual inputs (zooming, frame selection) during reasoning by using curiosity-driven reinforcement learning to overcome the model's tendency to rely solely on text.
Core Problem
Current VLMs reason purely in text space (Chain-of-Thought), preventing them from actively inspecting fine-grained visual details like tiny objects or specific video frames.
Why it matters:
- Purely textual reasoning limits accuracy on visually intensive tasks (e.g., counting small objects, reading embedded text)
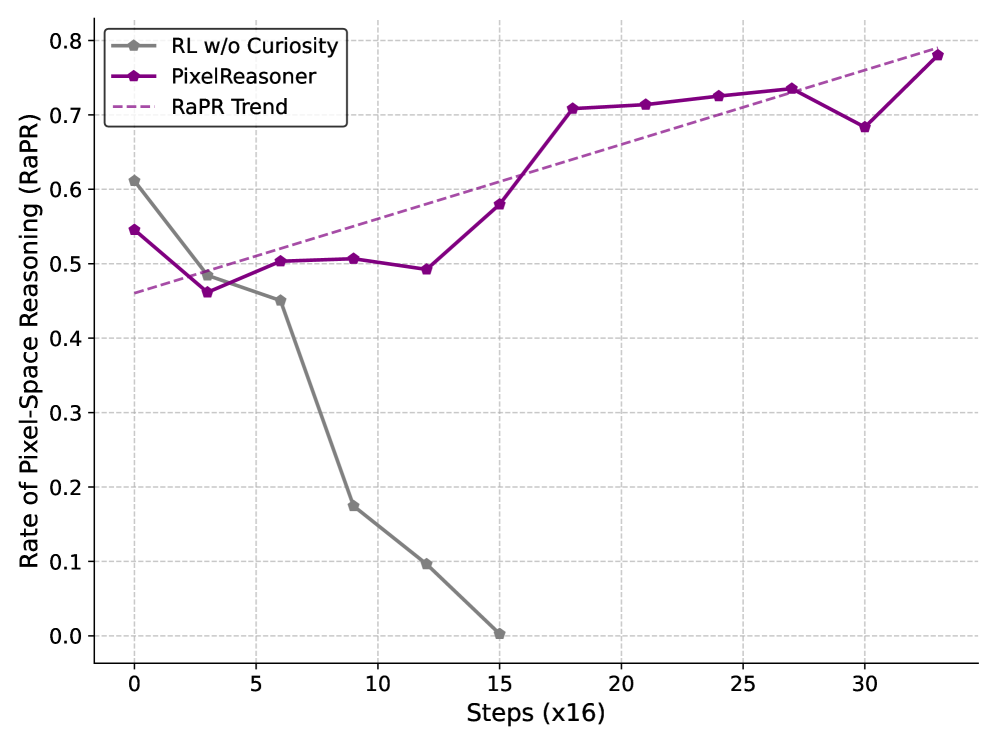
- Models suffer from a 'learning trap': they avoid using new visual tools because initial attempts fail, causing them to revert to safe but less accurate textual reasoning
- Lack of direct interaction hinders the depth of understanding in complex multimodal scenarios
Concrete Example:
When asked to count tiny objects in a crowded scene, a standard VLM might hallucinate a count based on a global image view. Pixel Reasoner would generate a 'zoom-in' action, retrieve a high-resolution patch of the specific region, count the objects in that patch, and then update its answer.
Key Novelty
Pixel-Space Reasoning with Curiosity-Driven RL
- Introduces 'pixel-space reasoning' where the VLM interleaves text generation with active visual operations (zoom-in, select-frame) to inspect images/videos directly
- Identifies a 'learning trap' where models abandon visual tools due to early failures; solves this via a curiosity-driven reward that intrinsically motivates the model to attempt visual operations
Architecture
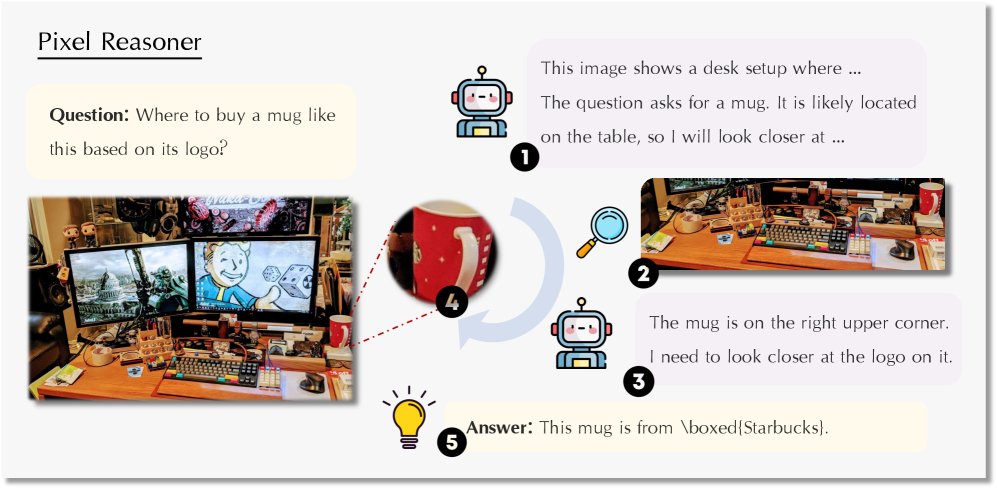
Concept of Pixel-Space Reasoning showing the interleaved generation of text and visual operations
Evaluation Highlights
- Achieves 84.3% on V* Bench, outperforming proprietary Gemini-2.5-Pro (79.2%) by 5.1 percentage points
- Attains 74% on TallyQA-Complex and 84% on InfographicsVQA, setting new state-of-the-art for open-source models
- Significantly improves over the base Qwen2.5-VL-7B model by overcoming the 'learning trap' through RL training
Breakthrough Assessment
9/10
Proposes a fundamental shift from text-only CoT to active visual interaction. The identification of the 'learning trap' and the curiosity-driven solution are significant methodological contributions with SOTA results.