📝 Paper Summary
Multimodal Benchmarking
Visual Mathematical Reasoning
MathVista is a comprehensive benchmark combining diverse visual contexts and mathematical reasoning tasks to quantify the performance gap between state-of-the-art foundation models and human capability.
Core Problem
Current benchmarks focus either on text-only math or simple visual scenes, failing to evaluate the fine-grained visual understanding and compositional reasoning required for mathematically intensive real-world tasks.
Why it matters:
- AI agents need strong visual math reasoning for applications in education, data analysis, and scientific discovery
- Existing VQA (Visual Question Answering) datasets on natural scenes lack the depth of mathematical reasoning found in charts, function plots, and geometry diagrams
- The capabilities of Large Multimodal Models (LMMs) in rigorous visual-mathematical contexts remain largely unexplored and unsystematically measured
Concrete Example:
When asked to identify a function as injective from a plot, Multimodal Bard correctly identifies the function type (parabola) but uses the Law of Cosines (geometry) instead of function properties, leading to a hallucinated explanation.
Key Novelty
Unified Visual-Math Benchmark (MathVista)
- Consolidates 28 existing multimodal datasets and introduces 3 new ones (IQTest, FunctionQA, PaperQA) to cover gaps in logical, algebraic, and scientific reasoning
- Defines a taxonomy of 7 mathematical reasoning types (e.g., algebraic, statistical) and 5 primary tasks (e.g., geometry problem solving, textbook QA) for fine-grained evaluation
- Implements a robust evaluation pipeline using GPT-4 as an answer extractor to standardize outputs from diverse foundation models
Architecture
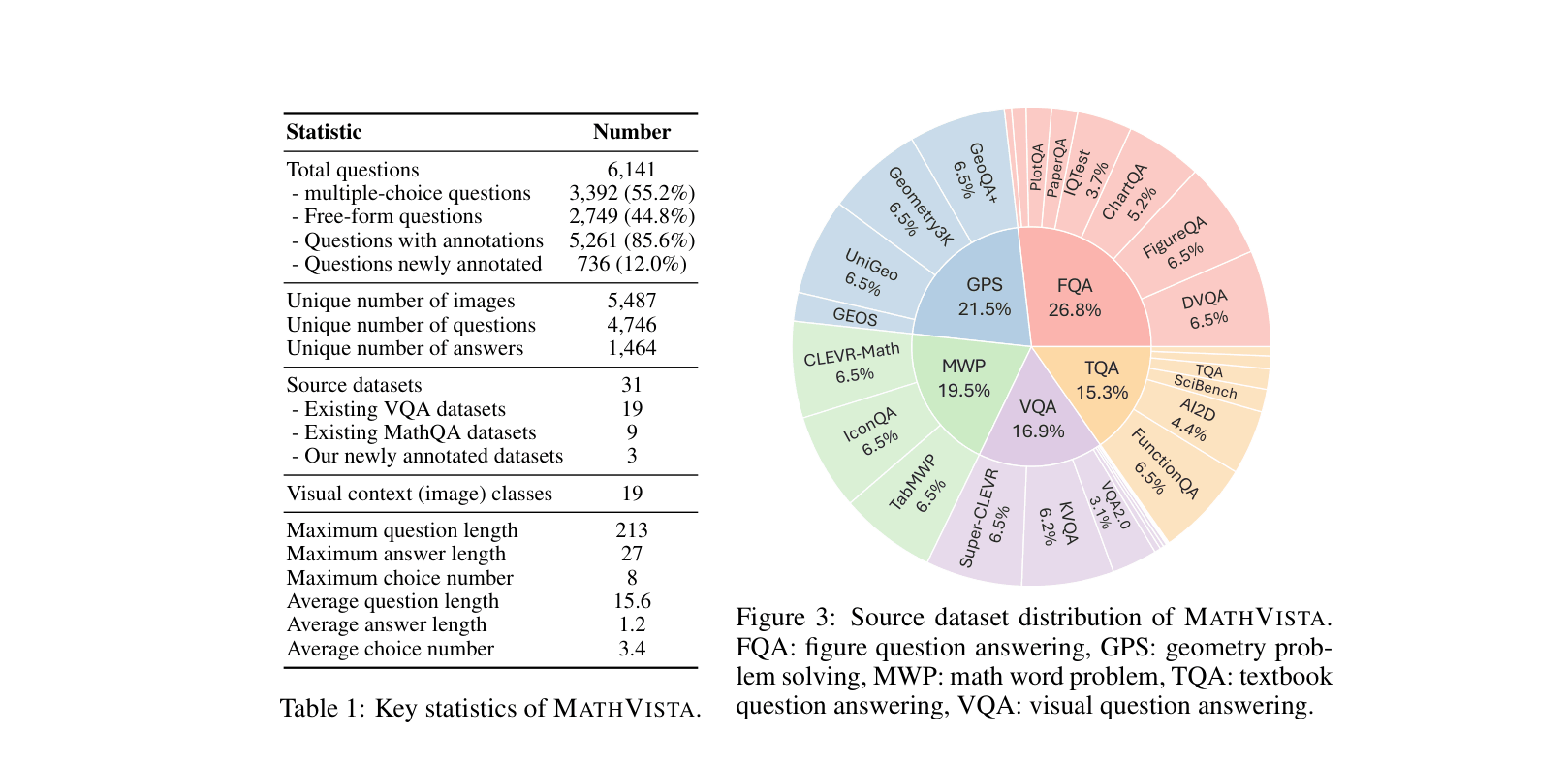
The composition and distribution of the MathVista dataset across different source datasets
Evaluation Highlights
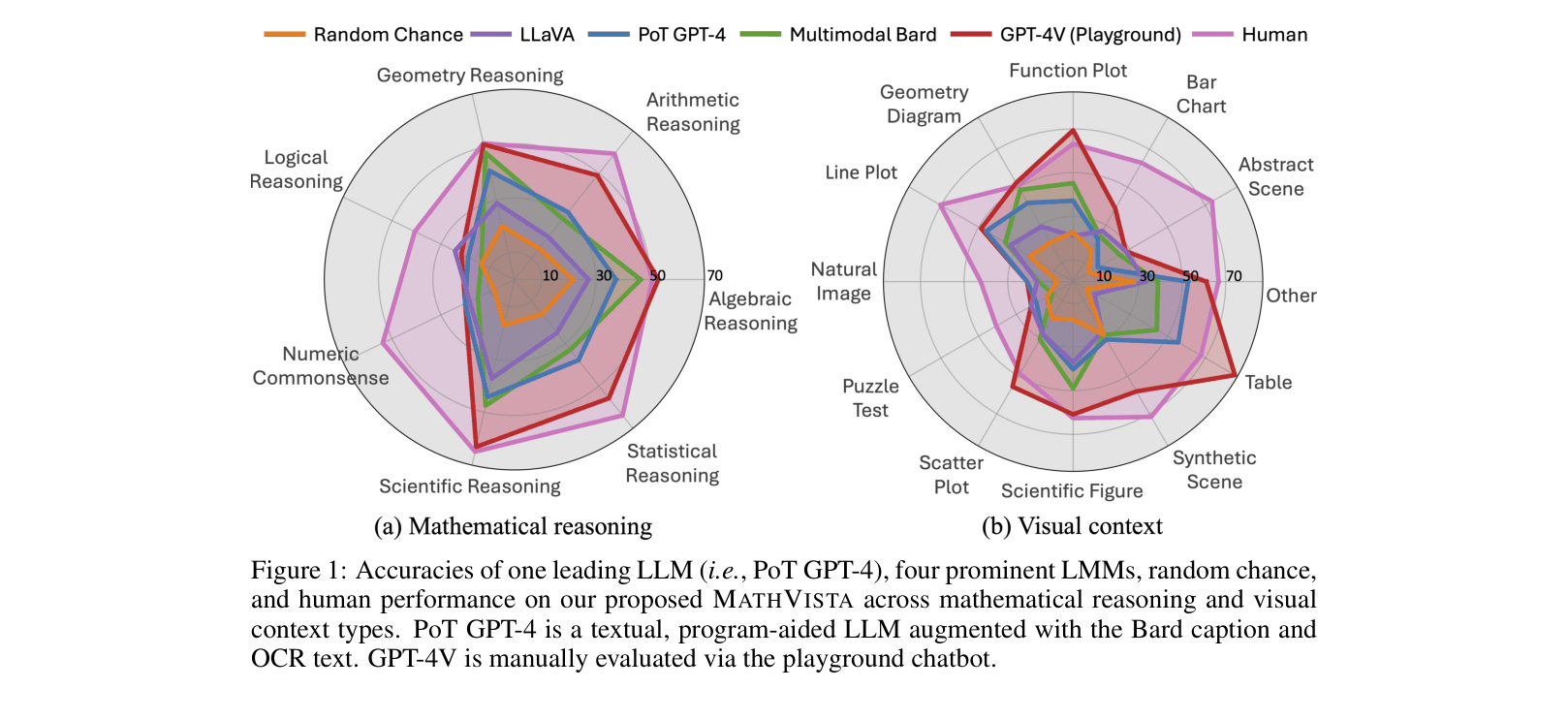
- GPT-4V achieves 49.9% overall accuracy, establishing a new state-of-the-art but trailing human performance (60.3%) by 10.4 percentage points
- GPT-4V outperforms Multimodal Bard (the second-best model) by 15.1 percentage points (49.9% vs 34.8%)
- Text-only GPT-4 augmented with captions and OCR achieves 33.9% with Program-of-Thought prompting, performing comparably to Multimodal Bard
Breakthrough Assessment
9/10
Sets a definitive standard for evaluating multimodal math reasoning. The gap revealed between GPT-4V and other models, and the remaining gap to humans, will drive future LMM research.