📊 Experiments & Results
Evaluation Setup
Zero-shot Question Answering on 11.5K questions across 30 subjects and 6 disciplines
Benchmarks:
- MMMU (Multimodal Question Answering (Expert Level)) [New]
Metrics:
- Micro-averaged Accuracy
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Leaderboard results demonstrate a significant gap between proprietary state-of-the-art models and open-source models, as well as a large gap between the best models and human experts. | ||||
| MMMU Test | Accuracy | 23.9 | 69.1 | +45.2 |
| MMMU Test | Accuracy | 44.7 | 55.7 | +11.0 |
| MMMU Validation | Accuracy | 56.8 | 88.6 | +31.8 |
| MMMU (Easy vs Hard) | Accuracy | 31.2 | 76.1 | +44.9 |
Experiment Figures

Performance of various models (GPT-4V, LLaVA, etc.) broken down by specific image types (Diagrams, Tables, Chemical Structures, etc.)
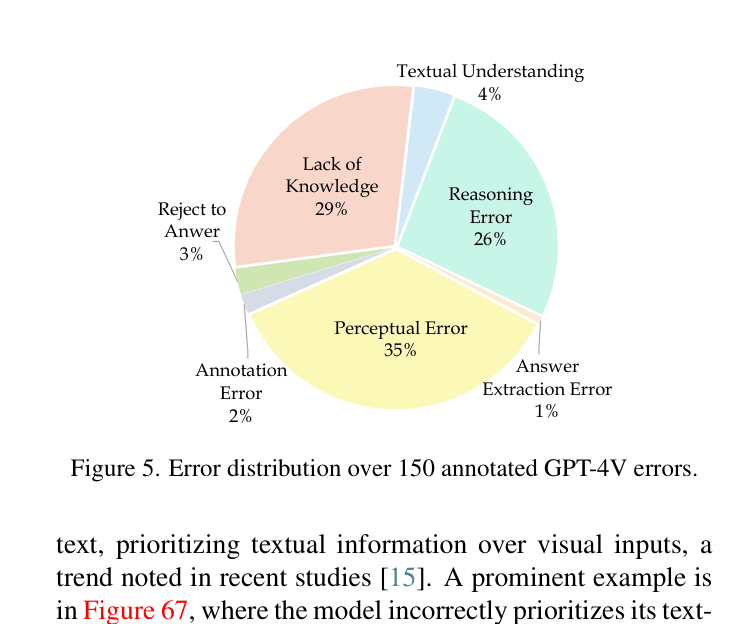
Distribution of error types for GPT-4V based on manual analysis of 150 incorrect samples
Main Takeaways
- Massive performance gap: Even SOTA models (GPT-4V/4o) represent a significant drop from Human Expert performance (88.6%), indicating the benchmark is far from solved
- Domain disparity: Models perform well in Humanities/Art but struggle in Science, Medicine, and Engineering which require complex visual reasoning
- Image type sensitivity: Models fail on uncommon image types (circuits, molecules) compared to photos, suggesting lack of training data diversity
- Reasoning bottleneck: Error analysis shows 26% of errors are due to flawed reasoning and 29% due to lack of domain knowledge, even when perception is correct