📝 Paper Summary
LLM Reasoning
Reinforcement Learning (RL)
Exploration vs. Exploitation
The paper improves LLM reasoning by adding a clipped, gradient-detached entropy term to the reinforcement learning advantage function, encouraging pivotal and reflective tokens without altering the original optimization direction.
Core Problem
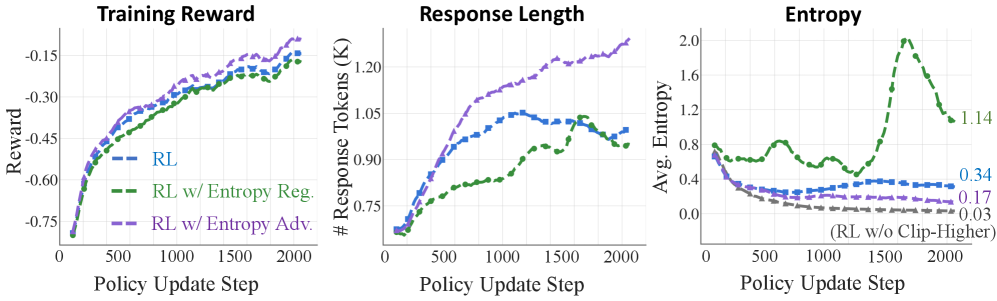
Current RL methods for LLMs (like RLVR) focus on accuracy-driven exploitation, causing models to converge on narrow, over-optimized behaviors and lose the capacity to explore alternative reasoning paths.
Why it matters:
- Pure exploitation leads to performance plateaus where models fail to sustain multi-step reasoning
- Models lose the incentive to self-reflect or try rare strategies in complex or underspecified settings
- Existing entropy methods (regularization) change the gradient flow, often destabilizing training rather than just encouraging exploration
Concrete Example:
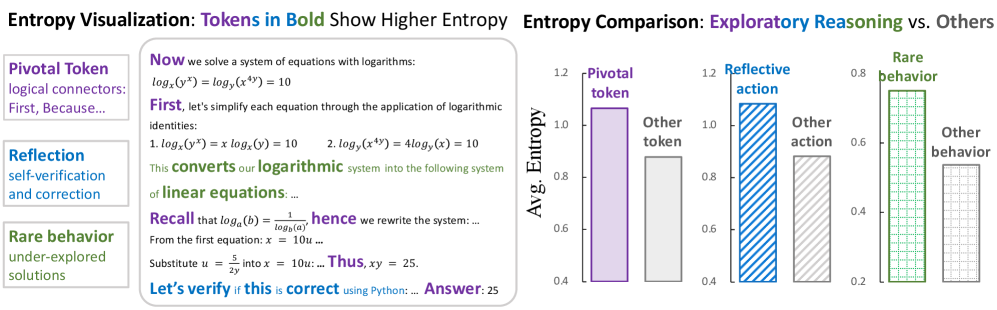
In mathematical reasoning, a base model might rarely convert logarithmic systems to linear equations. Standard RL might never discover this path if it's not initially high-probability, whereas an entropy-aware method detects the uncertainty at the decision point and encourages exploring that rare but valid strategy.
Key Novelty
Entropy-Based Advantage Shaping
- Correlates high entropy with 'exploratory reasoning' actions like pivotal connectors (e.g., 'however', 'therefore') and self-reflection ('let's verify')
- Modifies the RL advantage function by adding a term proportional to token entropy, making uncertain (exploratory) actions more attractive during training
- Uses a 'detached' and 'clipped' entropy term, meaning it influences the magnitude of the update but not the gradient direction, preserving the original policy's learning stability
Architecture
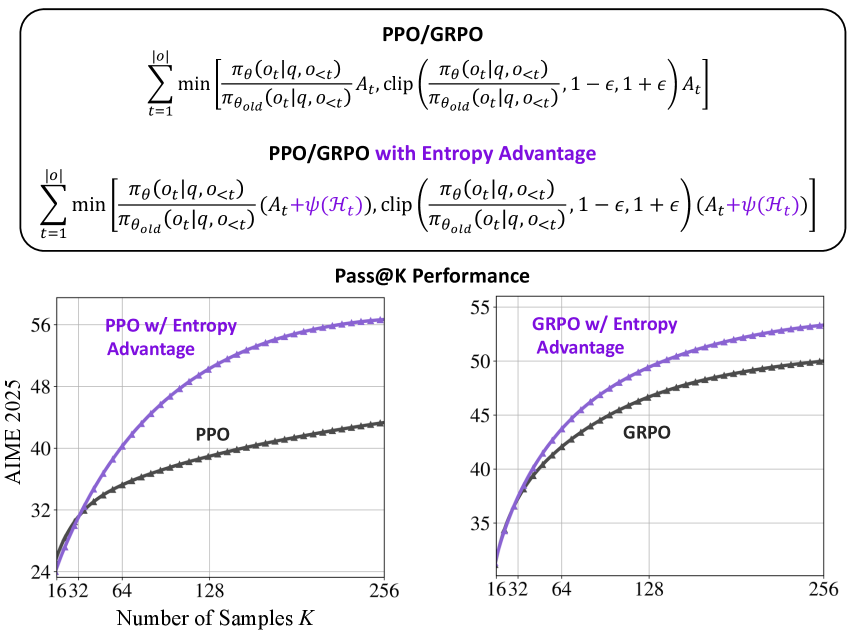
The mathematical modification to the advantage function.
Evaluation Highlights
- Consistently improves Pass@1 accuracy across different benchmarks using mainstream RL algorithms (GRPO and PPO)
- Achieves substantial improvements on Pass@K (an estimator of reasoning upper-bound), effectively pushing the boundaries of what the model can solve with multiple attempts
- Validates that high-entropy tokens strongly correlate with pivotal reasoning steps and reflective actions, confirming the theoretical motivation
Breakthrough Assessment
8/10
Simple yet effective one-line code modification that addresses the critical 'exploration-exploitation' trade-off in LLM reasoning, with strong empirical backing connecting entropy to reasoning semantics.