📝 Paper Summary
Multimodal Reasoning
Reinforcement Learning for LLMs
Vision-R1 enhances multimodal reasoning by initializing with a synthetically bridged image-text CoT dataset and fine-tuning via Reinforcement Learning with progressive length constraints to prevent overthinking.
Core Problem
Directly applying Reinforcement Learning to Multimodal LLMs fails to induce complex reasoning because models either get stuck in 'overthinking' loops (long, incorrect reasoning) or fail to activate reasoning due to sparse high-quality multimodal data.
Why it matters:
- Current MLLMs typically rely on direct prediction, exhibiting suboptimal performance on complex reasoning tasks compared to text-only models like OpenAI o1
- Manual construction of multimodal reasoning data often results in 'Pseudo-CoT' that lacks genuine cognitive processes like questioning, reflection, and verification
- Direct RL training (like DeepSeek-R1-Zero) is unstable for MLLMs without proper initialization, struggling to converge on complex visual tasks
Concrete Example:
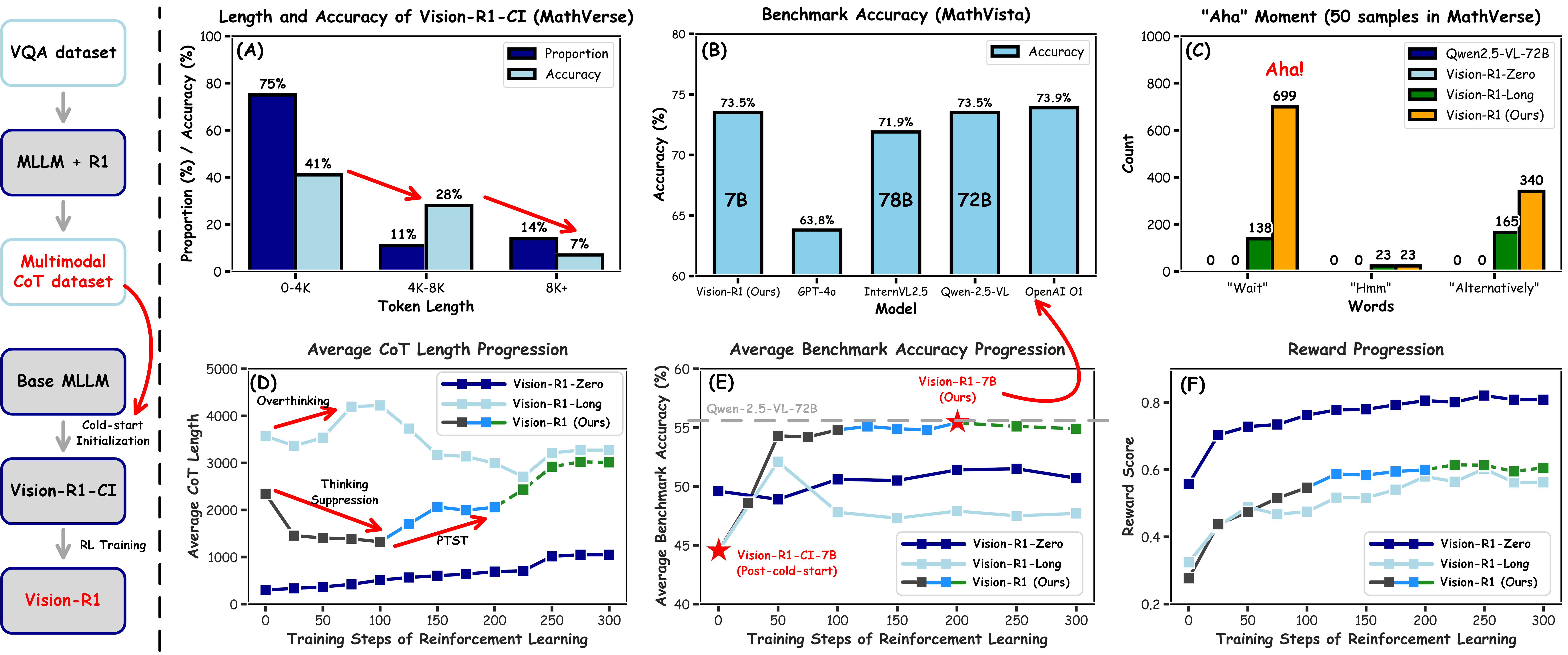
When directly trained with RL, a model might generate an extremely long reasoning chain (16K+ tokens) for a math problem but still reach the wrong answer, effectively 'overthinking' without internalizing the correct logic.
Key Novelty
Vision-R1 (Cold-Start + Progressive RL)
- Uses 'Modality Bridging' to generate data: an MLLM creates a detailed text description of an image based on a prompt, which is then fed to the strong text-reasoner DeepSeek-R1 to generate high-quality Chain-of-Thought data.
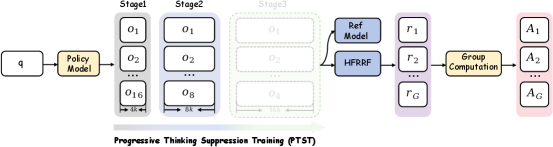
- Mitigates RL instability via 'Progressive Thinking Suppression Training' (PTST), which artificially caps reasoning length in early training stages to force concise correctness before allowing the model to attempt longer, more complex reasoning chains.
Architecture
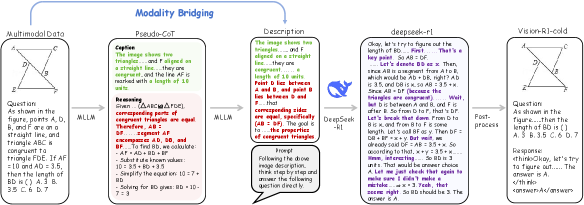
The data construction pipeline for the Vision-R1-cold dataset using Modality Bridging.
Evaluation Highlights
- Vision-R1-7B achieves 73.5% accuracy on MathVista, trailing the proprietary OpenAI o1 model by only 0.4%.
- Vision-R1-72B achieves 78.2% on MathVista, demonstrating scalability of the approach.
- Achieves ~6% average improvement across multimodal math benchmarks using only 10K math data points during the RL phase.
Breakthrough Assessment
8/10
Successfully transfers the 'R1' RL paradigm to Multimodal LLMs by solving the data scarcity and training stability issues. The performance of a 7B model rivalling proprietary models is significant.