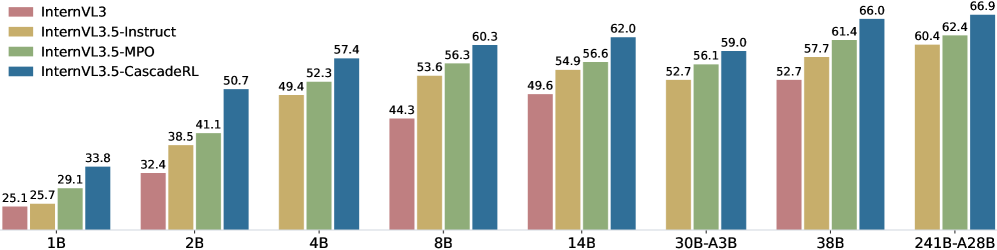📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Vision-Language Reasoning
Efficient Inference
InternVL3.5 improves multimodal reasoning and efficiency via a two-stage Cascade Reinforcement Learning framework and a dynamic visual router that adjusts token resolution based on image complexity.
Core Problem
Existing open-source MLLMs lag behind commercial models in complex reasoning and incur high computational costs when processing high-resolution visual contexts.
Why it matters:
- Commercial models like GPT-4o create a significant performance gap in agentic and reasoning tasks compared to open-source alternatives.
- High-resolution image understanding typically requires processing massive token counts, creating a bottleneck for real-world deployment latency and cost.
- Stable and scalable RL frameworks for MLLMs remain an open problem, with current methods often suffering from instability or limited performance ceilings.
Concrete Example:
When processing a simple image patch containing minimal detail (e.g., sky), standard models process it with the same high resolution (256 tokens) as a dense document patch, wasting compute. InternVL3.5-Flash detects this and compresses the sky patch to 64 tokens.
Key Novelty
Cascade RL & Visual Resolution Routing
- Cascade RL: A coarse-to-fine training strategy starting with offline RL (MPO) for stable warm-up and high-quality rollouts, followed by online RL (GSPO) to refine the output distribution and push the performance ceiling.
- Visual Resolution Router (ViR): A trainable module that dynamically decides the compression rate for each image patch, allowing the model to use fewer tokens for simple visual regions without losing accuracy.
Architecture
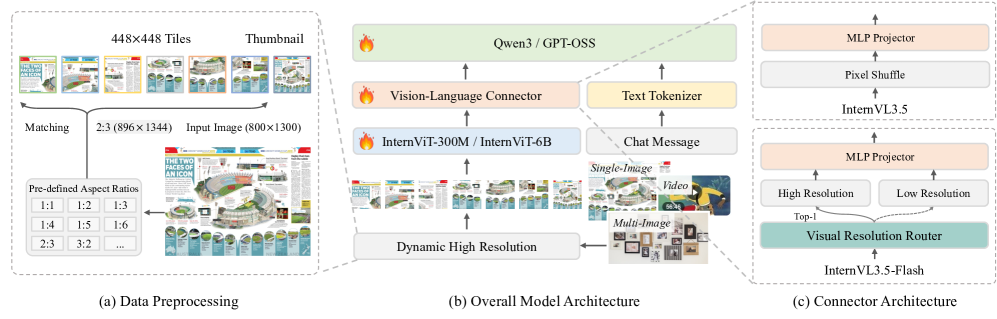
The architectural difference between InternVL3.5 and InternVL3.5-Flash, highlighting the Visual Resolution Router.
Evaluation Highlights
- InternVL3.5-241B-A28B achieves a score of 77.7 on MMMU, narrowing the gap with GPT-5 to 3.9% on general multimodal capabilities.
- Achieves up to 4.05x inference speedup compared to InternVL3 by combining the Visual Resolution Router and Decoupled Vision-Language Deployment.
- InternVL3.5-Flash reduces visual tokens by 50% while maintaining nearly 100% of the original model's performance.
Breakthrough Assessment
9/10
Significant engineering and methodological advances (Cascade RL, Dynamic Resolution) that effectively close the gap between open-source and top-tier proprietary models while addressing practical deployment costs.