📝 Paper Summary
Reinforcement Learning for Reasoning
RL Exploration
Policy Entropy
The paper identifies a predictable empirical law where policy entropy collapses exponentially during RL training, hindering exploration, and proposes methods to mitigate this by managing token-level covariance.
Core Problem
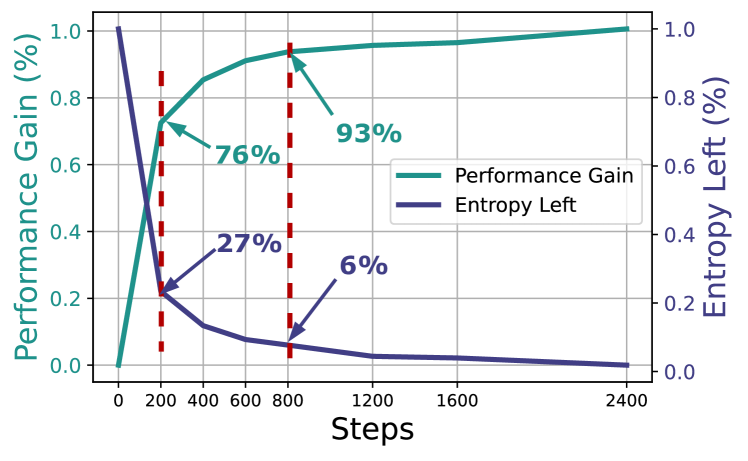
In reinforcement learning for LLMs, policy entropy collapses sharply to near zero early in training, causing the policy to become overly confident and stop exploring, which leads to premature performance saturation.
Why it matters:
- Scaling compute for RL (post-training) is expected to be the next frontier, but entropy collapse prevents continuous improvement
- Current methods struggle with the exploration-exploitation trade-off in reasoning tasks, where finding novel paths is critical
- Naive entropy regularization techniques (like standard entropy loss) are often ineffective for large reasoning models
Concrete Example:
During training on math problems, a model's entropy drops significantly within the first 200 steps (consuming 73% of total entropy change), causing it to repeatedly output the same high-confidence solution path rather than exploring potentially better reasoning strategies.
Key Novelty
Entropy-Performance Predictability and Covariance-based Entropy Control
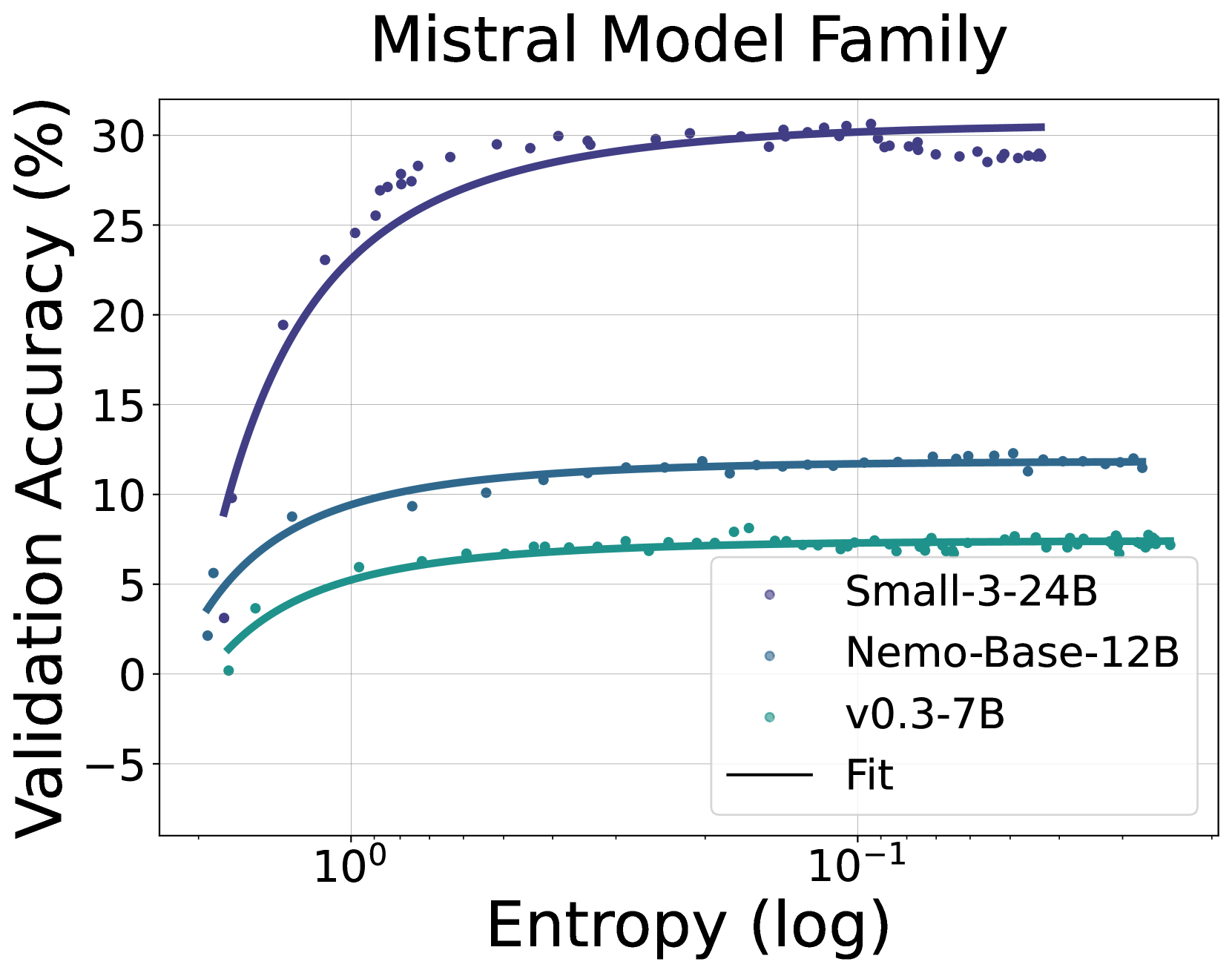
- Establishes an empirical law $R = -a \exp(\mathcal{H}) + b$ that predicts downstream performance $R$ from policy entropy $\mathcal{H}$, implying a deterministic performance ceiling when entropy is exhausted
- Theoretically derives that entropy decay is driven by the covariance between action probability and advantage, meaning high-confidence, high-advantage actions rapidly reduce entropy
- Proposes Clip-Cov and KL-Cov strategies to actively manage entropy by targeting and restricting updates on tokens with high covariance
Architecture
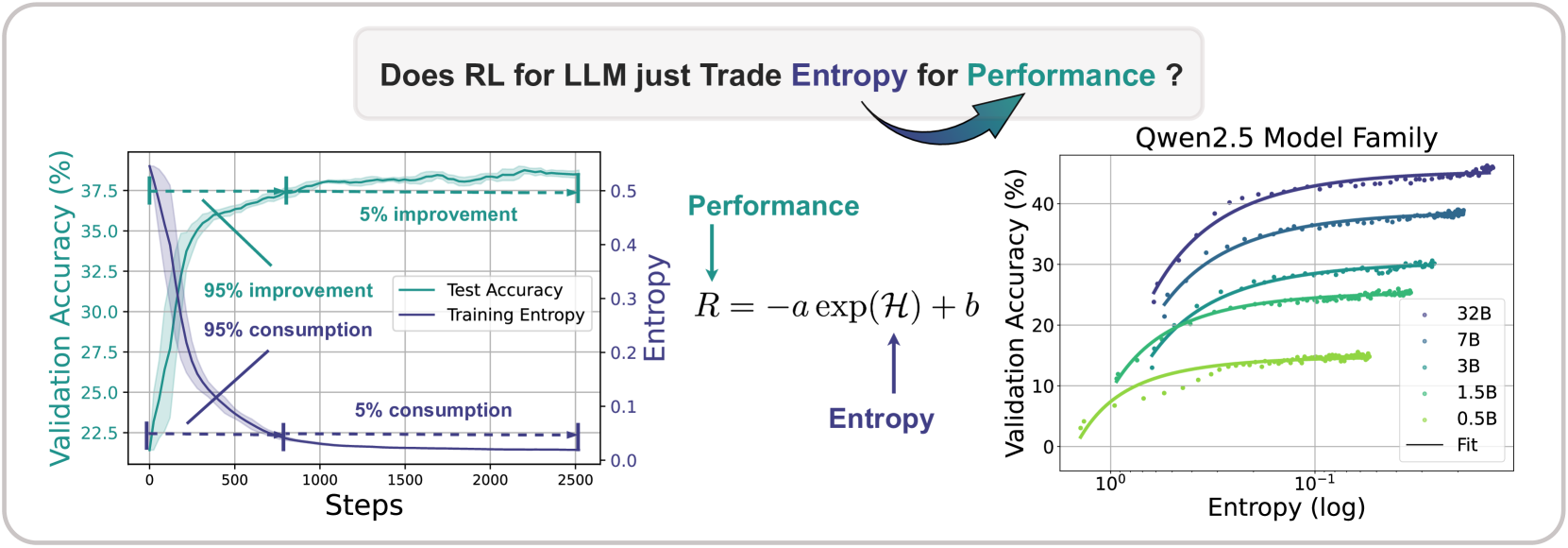
The empirical relationship between policy entropy and validation performance, showing the exponential fit curve alongside the concept of 'Entropy Collapse'.
Evaluation Highlights
- The empirical formula $R = -a \exp(\mathcal{H}) + b$ fits entropy-performance curves across 11 models and 4 RL algorithms with high precision
- Predicts final performance using only the first 36 training steps with an average RMSE of 0.5% on math tasks (Qwen2.5 family)
- Proposed methods (Clip-Cov/KL-Cov) help models escape entropy collapse, achieving better reasoning performance than standard baselines
Breakthrough Assessment
8/10
Strong empirical finding (predictable entropy-performance law) akin to scaling laws, backed by theoretical derivation of the mechanism. The proposed solution is a logical consequence of the analysis.