📝 Paper Summary
Video Reasoning
Multimodal Reinforcement Learning
Video-R1 adapts the DeepSeek-R1 reinforcement learning paradigm to video MLLMs by introducing a contrastive temporal reward that forces models to rely on frame order rather than static shortcuts.
Core Problem
Standard RL methods like GRPO lack explicit signals for temporal reasoning, causing models to exploit 'shortcuts' by answering based on single frames rather than understanding event progression.
Why it matters:
- Models often guess answers from static visual cues (e.g., seeing a stove and guessing 'cooking') without processing the actual sequence of events, failing at causal reasoning
- Existing video datasets focus on recognition rather than complex reasoning, limiting the effectiveness of reinforcement learning for dynamic tasks
- Directly applying text-based RL (like DeepSeek-R1) to video fails to incentivize the specific capability of temporal modeling
Concrete Example:
When asked 'What happens after the man opens the fridge?', a standard model might identify 'cooking' from a later frame and answer correctly even if the frames are shuffled. T-GRPO detects this shortcut by comparing performance on ordered vs. shuffled frames, rewarding the model only if it fails on the shuffled version but succeeds on the ordered one.
Key Novelty
Temporal Group Relative Policy Optimization (T-GRPO)
- Modifies the GRPO algorithm to include a contrastive temporal reward: the model generates answers for both ordered and shuffled video frames
- Assigns positive rewards only when the model's accuracy on ordered frames strictly exceeds its accuracy on shuffled frames, penalizing reliance on static frame content
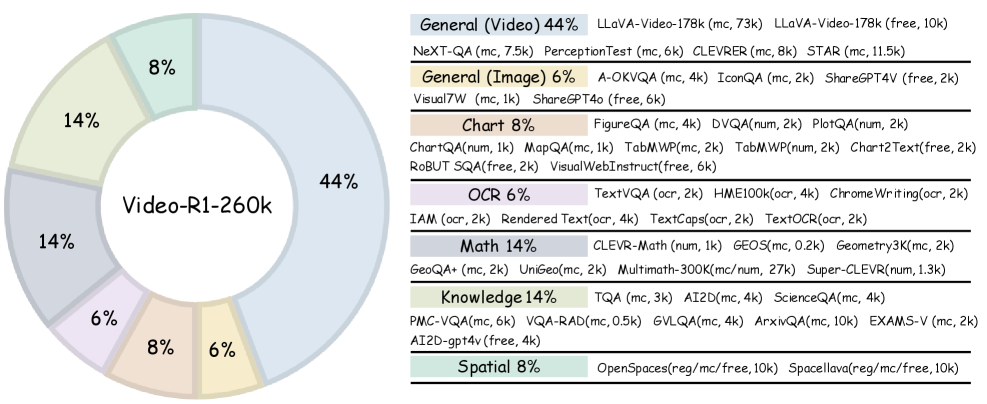
- Combines image-based reasoning data (for general logic) with video data (for temporal logic) to overcome the scarcity of high-quality video reasoning benchmarks
Architecture
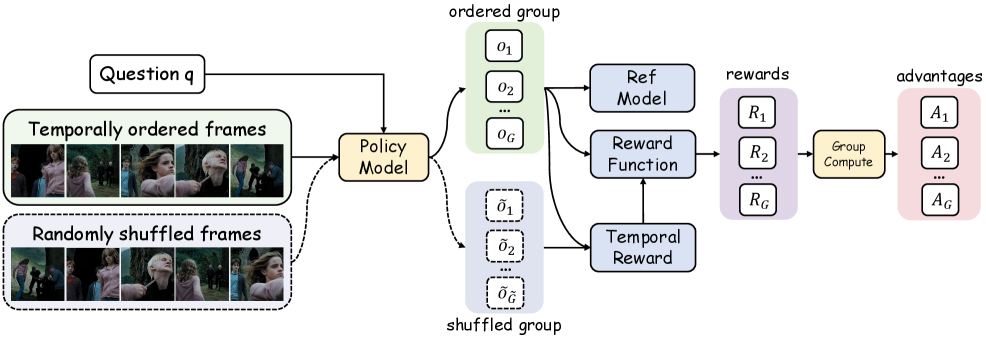
The T-GRPO (Temporal Group Relative Policy Optimization) training process.
Evaluation Highlights
- Video-R1-7B achieves 37.1% accuracy on the VSI-Bench (Video Spatial Intelligence) benchmark, explicitly stated to outperform the proprietary GPT-4o model
- Demonstrates significant improvements across general video benchmarks including VideoMMMU, MVBench, and TempCompass (qualitative claim, exact deltas not in text)
Breakthrough Assessment
8/10
First systematic application of the R1 reasoning paradigm to video. Addresses the critical 'temporal shortcut' flaw in video MLLMs with a clever contrastive RL mechanism (T-GRPO).