📝 Paper Summary
Mathematical Reasoning in LLMs
Reinforcement Learning for Reasoning
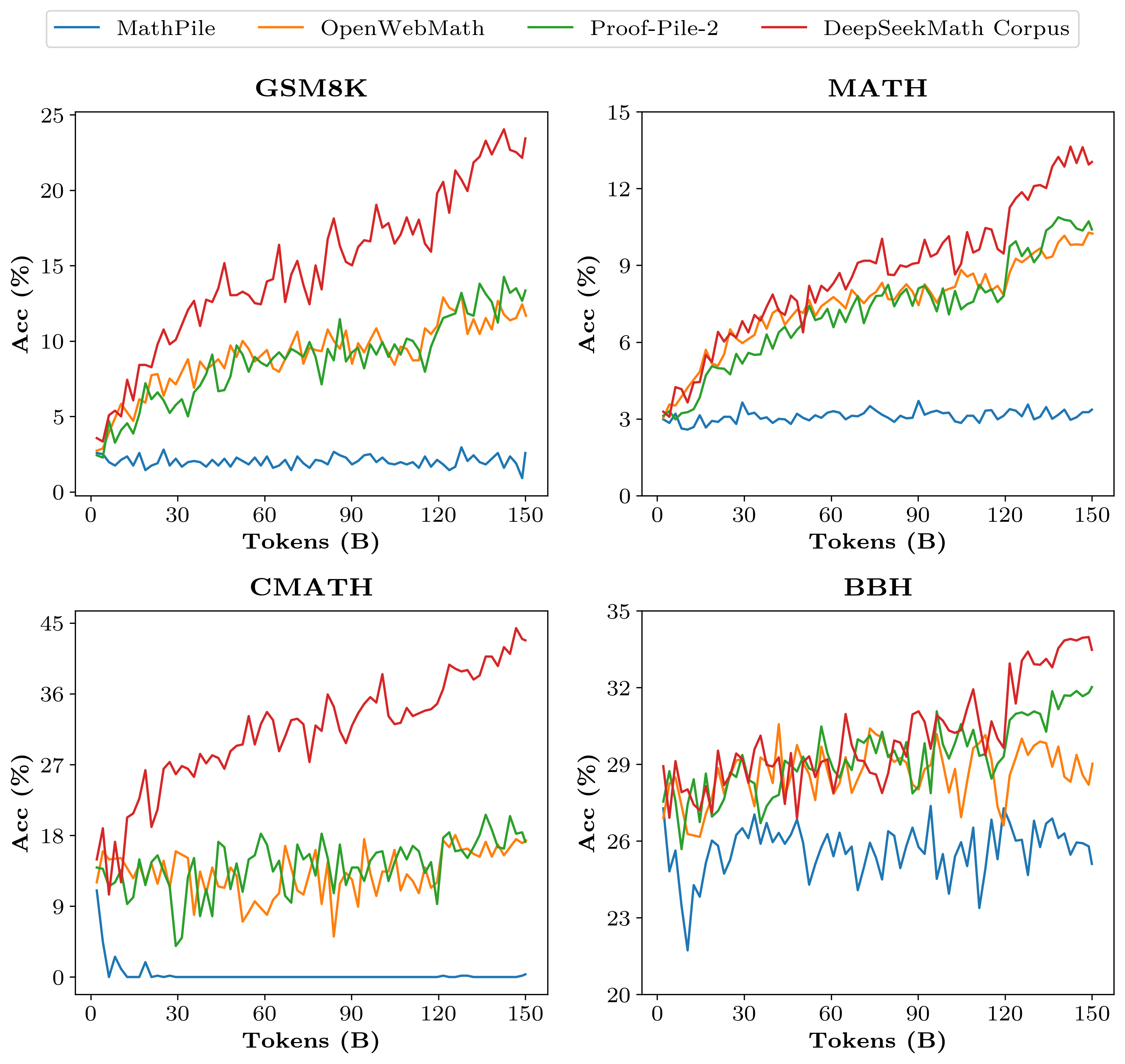
Data Curation for Pre-training
DeepSeekMath achieves state-of-the-art open-source mathematical reasoning by mining 120B high-quality math tokens from the web and introducing Group Relative Policy Optimization (GRPO) to efficiently reinforce reasoning capabilities.
Core Problem
Open-source models lag significantly behind proprietary models (GPT-4, Gemini-Ultra) in mathematical reasoning, partly due to the scarcity of high-quality, open math pre-training data and inefficient RL methods.
Why it matters:
- Math reasoning is a proxy for complex structural thinking, but high-performance models are closed-source
- Standard web crawls (Common Crawl) contain vast math knowledge but are noisy and hard to filter effectively using static classifiers
- Existing RL methods like PPO are memory-intensive and often require a separate critic model, making them expensive to scale for reasoning tasks
Concrete Example:
A standard fastText classifier trained only on OpenWebMath misses niche math forums in Common Crawl because it lacks diverse positive examples. DeepSeekMath's iterative mining finds these by identifying 'math-heavy' domains (like mathoverflow.net) and re-annotating uncollected URLs to retrain the classifier.
Key Novelty
DeepSeekMath Corpus & Group Relative Policy Optimization (GRPO)
- Iterative FastText Mining: Instead of a static filter, the paper uses an iterative loop where a classifier mines math content, high-density domains are identified, and new positive examples are manually annotated to retrain the classifier, eventually recalling 120B math tokens.
- GRPO (Group Relative Policy Optimization): An RL algorithm that eliminates the critic model entirely. Instead of estimating a value function, it samples a group of outputs for the same prompt and uses the group average as the baseline to calculate advantages, saving memory.
Architecture
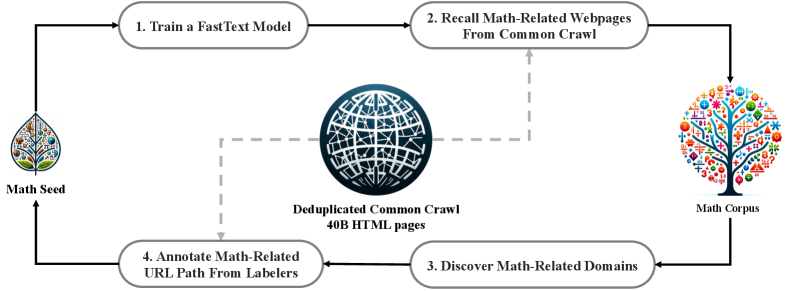
The iterative data collection pipeline for the DeepSeekMath Corpus.
Evaluation Highlights
- 51.7% accuracy on the competition-level MATH benchmark (DeepSeekMath-RL 7B), approaching GPT-4 and Gemini-Ultra performance levels.
- 88.2% accuracy on GSM8K using GRPO, an improvement of +5.3% over the instruction-tuned baseline solely through reinforcement learning on in-domain data.
- DeepSeekMath-Base 7B outperforms Minerva 540B on MATH (36.2% vs 33.6%) despite being ~77x smaller, highlighting the value of high-quality pre-training data.
Breakthrough Assessment
9/10
The model sets a new standard for open-source math reasoning at the 7B scale, beating 70B+ models. GRPO is a significant methodological efficiency gain for RLHF, and the data pipeline offers a reproducible blueprint for domain adaptation.