📝 Paper Summary
Chain-of-Thought (CoT) Reasoning
Latent Space Reasoning
Efficient LLM Inference
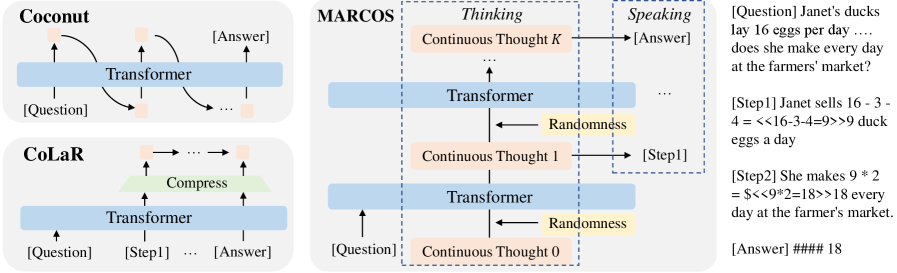
MarCos decouples reasoning from token generation by modeling thought as a Markov chain of continuous vectors, achieving faster inference and higher accuracy than token-based Chain-of-Thought.
Core Problem
Standard Chain-of-Thought forces models to 'think while speaking' token-by-token, creating an information bottleneck due to discretization and slowing down inference significantly.
Why it matters:
- Autoregressive generation of thousands of CoT tokens is computationally expensive and slow.
- Discretizing thoughts into tokens at every step causes information loss between reasoning states.
- Forcing the model to generate tokens immediately limits the ability to plan or deliberate before outputting an answer.
Concrete Example:
In a complex math problem, a standard LLM must output every intermediate calculation step as text tokens. This forces it to commit to a path word-by-word. MarCos instead updates internal continuous vectors (thoughts) multiple times without outputting text, only generating the final answer or requested intermediate steps when ready.
Key Novelty
Markov Chain of Continuous Thoughts (MarCos)
- Separates 'thinking' (transitioning continuous latent states) from 'speaking' (decoding states into text), allowing the model to reason without generating tokens.
- Models reasoning as a Conditional Hidden Markov Model (cHMM) where thoughts are hidden variables and text is the observable emission.
- Introduces a randomness predictor that maps thoughts to a multimodal distribution, enabling step-level control over reasoning diversity rather than token-level sampling.
Architecture
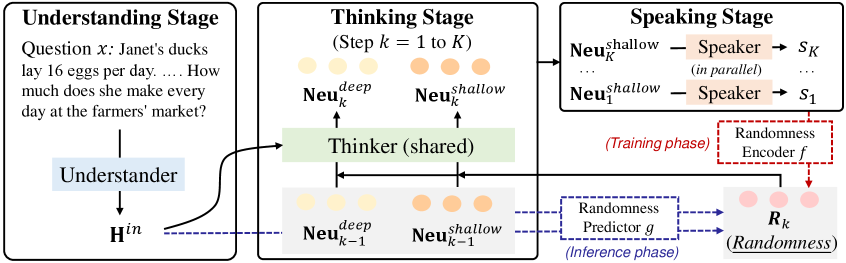
The MarCos inference pipeline showing the separation of Understanding, Thinking, and Speaking phases.
Evaluation Highlights
- +4.7% accuracy on GSM8K compared to token-based CoT (Qwen2.5-0.5B backbone) while being up to 15.7x faster.
- +8.66% accuracy improvement over CoLaR (best previous continuous reasoning baseline) on GSM8K.
- Demonstrates strong generalization with up to +4.68% gains on out-of-domain benchmarks SVAMP and MultiArith.
Breakthrough Assessment
9/10
First latent reasoning method to match or outperform explicit CoT accuracy while offering massive speedups. The decoupling of thought and language aligns better with human cognition and solves the CoT efficiency bottleneck.