📊 Experiments & Results
Evaluation Setup
Multimodal tasks covering generation, editing, and visual reasoning under varying compute budgets (1 to 10 rounds).
Benchmarks:
- OneIG-Bench (Compositional text-to-image generation)
- CompBench (Multi-object compositional editing)
- ImgEdit (Multi-turn image editing)
- MIRA (Out-of-distribution visual reasoning)
Metrics:
- Instruction Following Accuracy
- Human Preference Score (0-10)
- Visual Reasoning Accuracy
- Statistical methodology: Human evaluation with 3 expert annotators, Krippendorff’s alpha reported (0.82).
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Test-time scaling significantly improves performance across generation and editing tasks as the number of inference rounds (C) increases. | ||||
| MIRA | Visual Reasoning Accuracy Improvement | 0.0 | 53.33 | +53.33 |
| CompBench | Editing Score Improvement | 0.0 | 5.56 | +5.56 |
| ImgEdit | Multi-turn Editing Score Improvement | 0.0 | 225.19 | +225.19 |
| OneIG-Bench | Instruction Following Improvement | 0.0 | 10.34 | +10.34 |
Experiment Figures

Scaling curves showing performance vs. compute for Sequential CoT vs. Best-of-N parallel sampling.
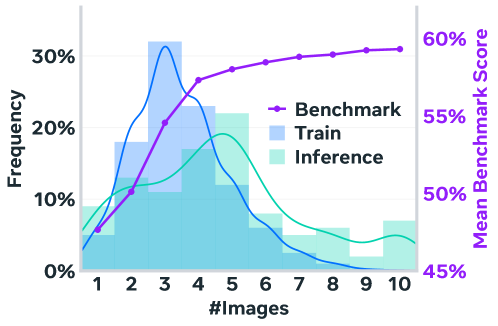
Generalization of reasoning chain length from training to inference.
Main Takeaways
- Models trained on short reasoning chains (avg 3.6 rounds) generalize to longer chains (avg 4.7 rounds) at test time, continuing to improve performance.
- Sequential chain-of-thought scaling is more compute-efficient than parallel best-of-N sampling, achieving similar results with 2.5x less cost.
- Training on generative refinement tasks transfers to improved understanding (visual reasoning) on MIRA, suggesting a unified capability.
- Cognitive behaviors like verification, subgoal decomposition, and content memory emerge naturally from the agentic data training.