📝 Paper Summary
Video Understanding
Multimodal Large Language Models (MLLMs)
Efficient Inference
Long, human-like Chain-of-Thought reasoning is unnecessary for effective video understanding; models trained via direct RL to produce concise reasoning on compressed visual tokens achieve better performance with significantly lower latency.
Core Problem
Chain-of-Thought (CoT) in video MLLMs incurs massive computational overhead due to redundant visual tokens and long text generation, while requiring expensive supervised fine-tuning (SFT) data.
Why it matters:
- The combination of high-resolution video inputs (thousands of tokens) and verbose CoT outputs creates memory and latency bottlenecks that hinder deployment
- Standard CoT training pipelines rely on two-stage training (SFT + RL) with costly human-annotated reasoning traces, slowing down development cycles
- Empirical benchmarks reveal that prompting base models for concise reasoning fails, and token compression degrades performance significantly when applied to unadapted models
Concrete Example:
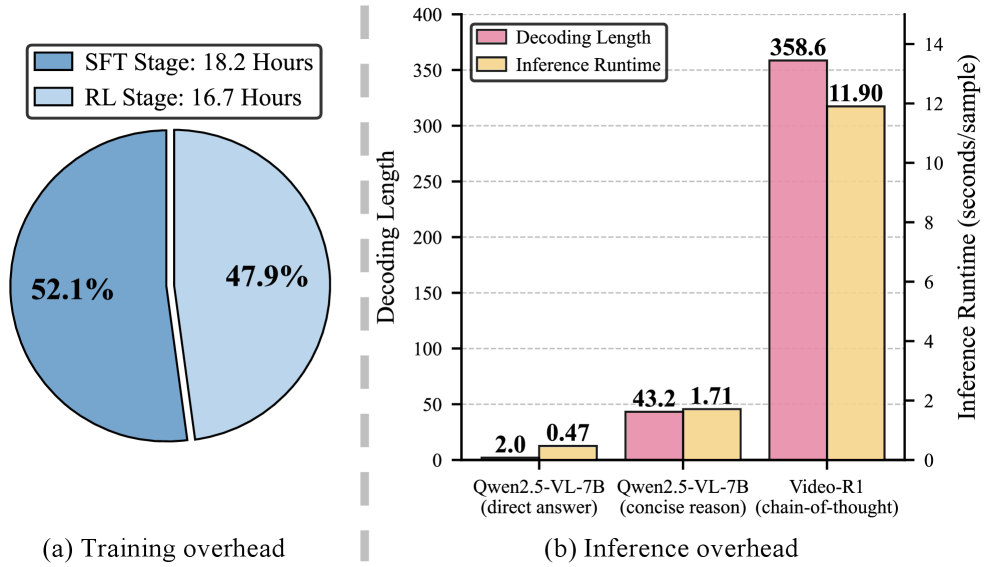
When a standard CoT model (like Video-R1) answers a video question, it generates 'pondering' phrases like 'Hmm, let's think...' and long intermediate steps, taking ~11.9 seconds. The proposed concise model outputs a brief rationalization and the answer in ~1.7 seconds, while maintaining or exceeding accuracy.
Key Novelty
Concise-Reasoning RL Framework with Integrated Token Compression
- Replaces the standard two-stage CoT training (SFT + RL) with a single-stage Reinforcement Learning process (using GRPO) that rewards correct answers without requiring annotated reasoning traces
- Integrates visual token compression (pruning/merging) directly into the training loop, allowing the model to adapt to sparse visual information rather than just applying compression at inference time
- Enforces a 'concise reasoning' decoding style that generates short, dense rationales instead of lengthy, rambling chains of thought
Architecture
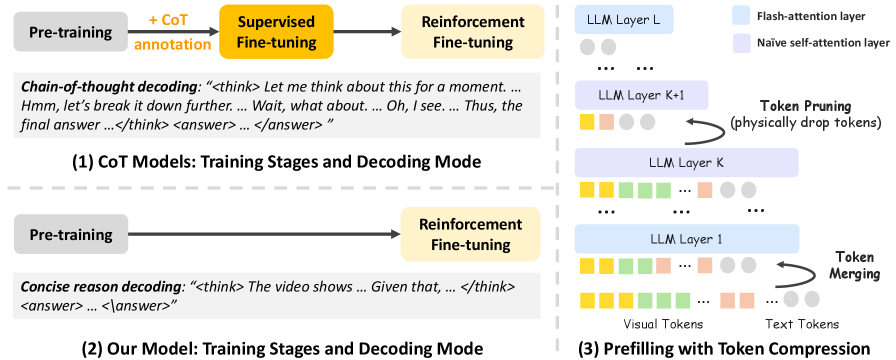
The proposed efficient post-training framework compared to traditional CoT pipelines.
Evaluation Highlights
- +1.6% accuracy improvement on VideoMME (60.3 vs 58.7) compared to the base Qwen2.5-VL model, while outperforming the lengthy Video-R1 baseline (59.5)
- ~7x reduction in inference latency compared to standard CoT models (1.71s vs 11.9s) due to concise decoding and token compression
- Eliminates the Supervised Fine-Tuning (SFT) stage entirely, reducing training time from >30 hours (for Video-R1) to ~5 hours
Breakthrough Assessment
8/10
Challenge the prevailing orthodoxy that 'more tokens + longer reasoning = better performance' in video LLMs. By proving that concise RL-trained models outperform verbose CoT models, it offers a highly practical path for efficient deployment.