📝 Paper Summary
Chain-of-Thought Prompting
In-Context Learning
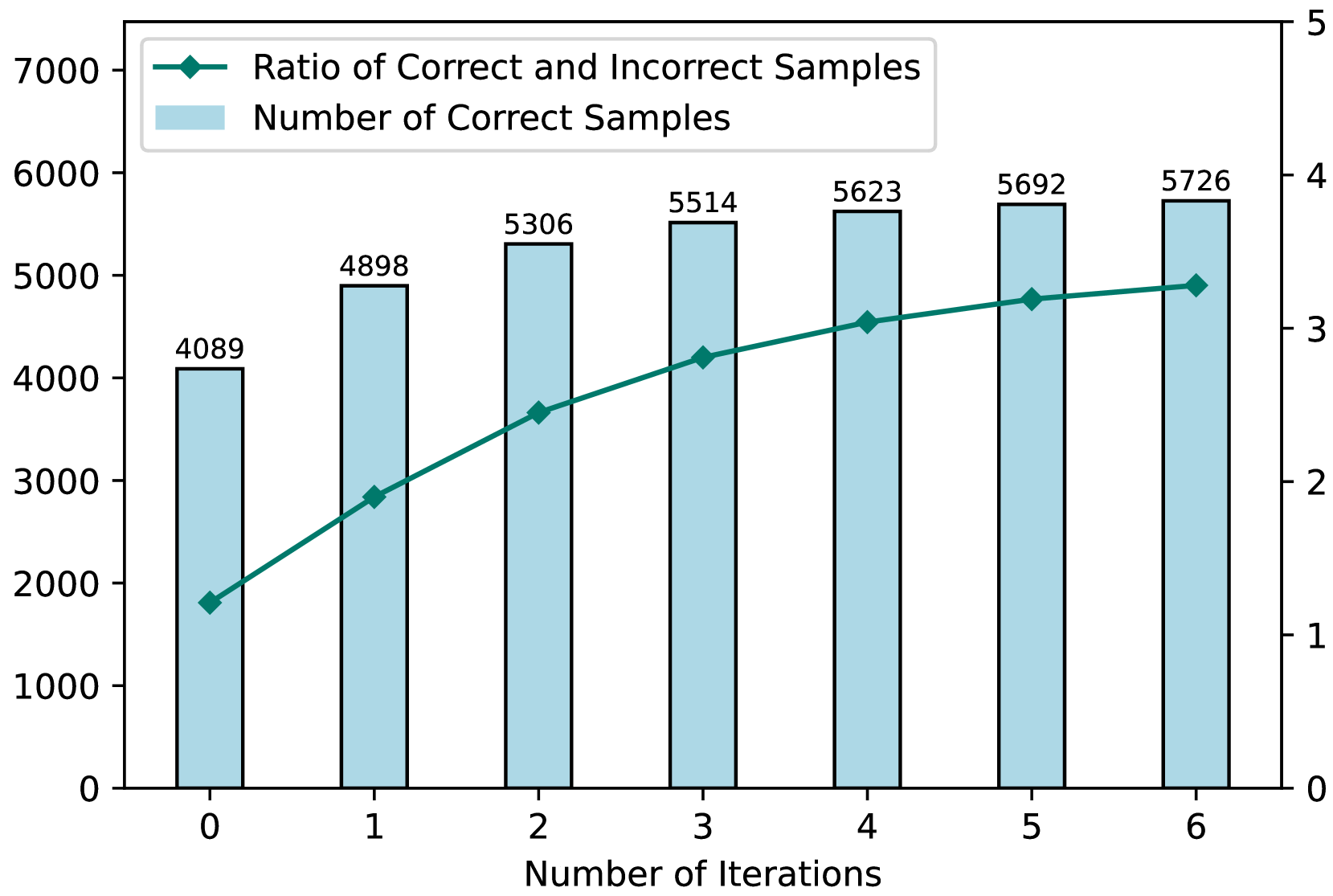
Iter-CoT selects challenging yet answerable questions and iteratively corrects their reasoning chains using the LLM itself to create high-quality few-shot demonstrations.
Core Problem
Standard automatic Chain-of-Thought (CoT) methods often generate erroneous reasoning chains or select demonstrations with inappropriate difficulty levels (too simple or too complex), hurting LLM performance.
Why it matters:
- Incorrect reasoning chains in demonstrations propagate errors during inference, significantly reducing accuracy
- Questions that are too simple fail to guide complex reasoning, while overly complex ones confuse the model on simpler tasks
- Manual annotation of high-quality reasoning chains is costly, subjective, and difficult to scale across new tasks
Concrete Example:
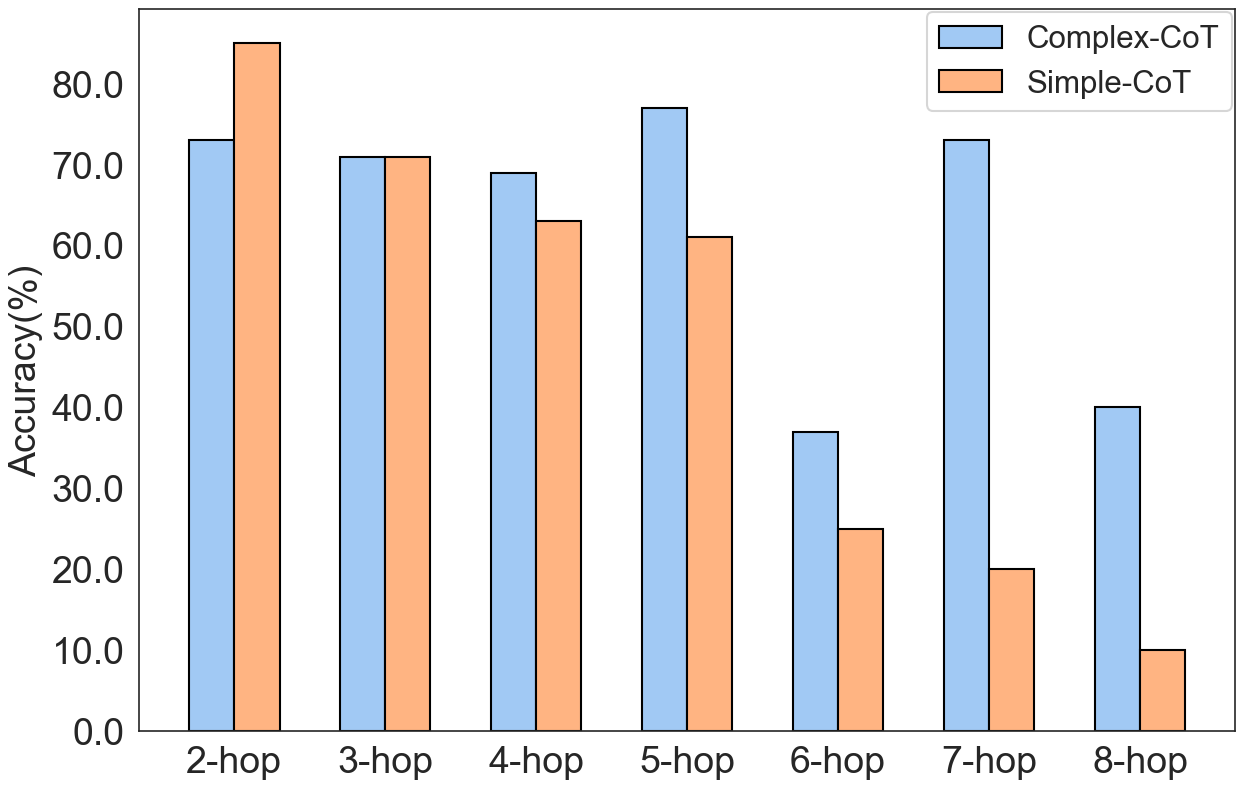
In Date Understanding, a randomly sampled correct exemplar fails to guide the model because its reasoning is trivial. Conversely, Iter-CoT prompts the model to fix an initially incorrect answer to a harder question, producing a robust reasoning chain that correctly guides the test instance.
Key Novelty
Iterative Bootstrapping for CoT Demonstration Selection (Iter-CoT)
- Identifies 'challenging yet answerable' questions by finding instances the model initially gets wrong but can self-correct when prompted ('Your answer is not right...')
- Uses a summarization step ('Give me a complete solution...') to consolidate the self-correction dialogue into a clean, comprehensive reasoning chain for use as a demonstration
Architecture
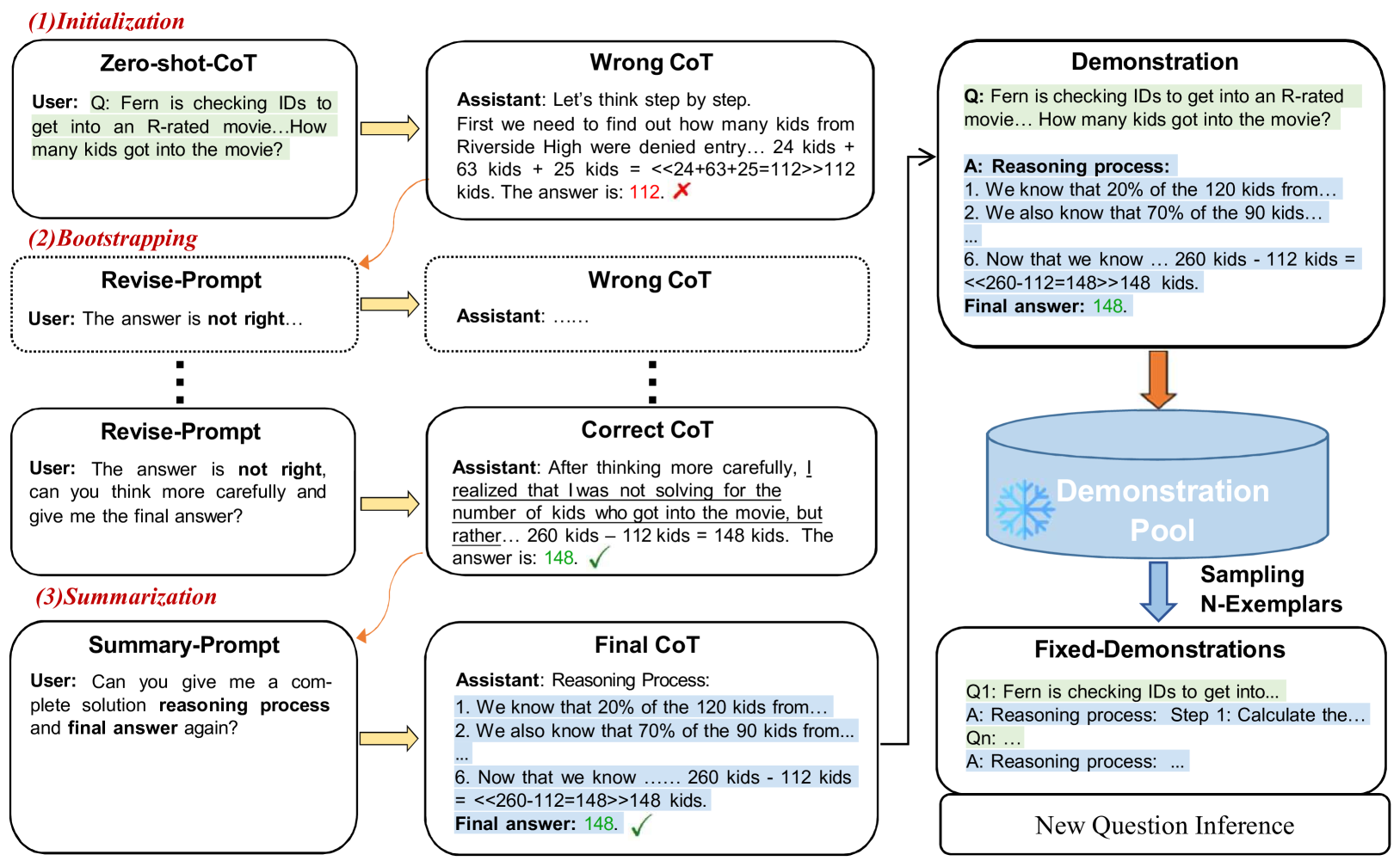
The flowchart of Iter-CoT, detailing the Demonstration Pool Construction and Inference stages.
Evaluation Highlights
- Achieves 83.8% average accuracy on five arithmetic datasets (GSM8K, AddSub, SingleEq, SVAMP, ASDiv), surpassing Complex-CoT (82.2%) by 1.6%
- Outperforms Manual-CoT by 3.8% and Random-CoT by 6.1% on average across ten datasets using GPT-3.5-turbo
- Improves Letter Concatenation accuracy by ~7% over previous best methods (Auto-CoT) using labeled data
Breakthrough Assessment
8/10
Significantly improves automatic CoT generation by leveraging self-correction, addressing both correctness and difficulty selection without needing external heavy supervision.