📝 Paper Summary
Chain-of-Thought (CoT) Analysis
Reasoning Structure
Explainability
LCoT2Tree converts linear Long Chain-of-Thought reasoning into hierarchical trees, revealing that structural patterns like backtracking and verification predict answer correctness better than sequence length.
Core Problem
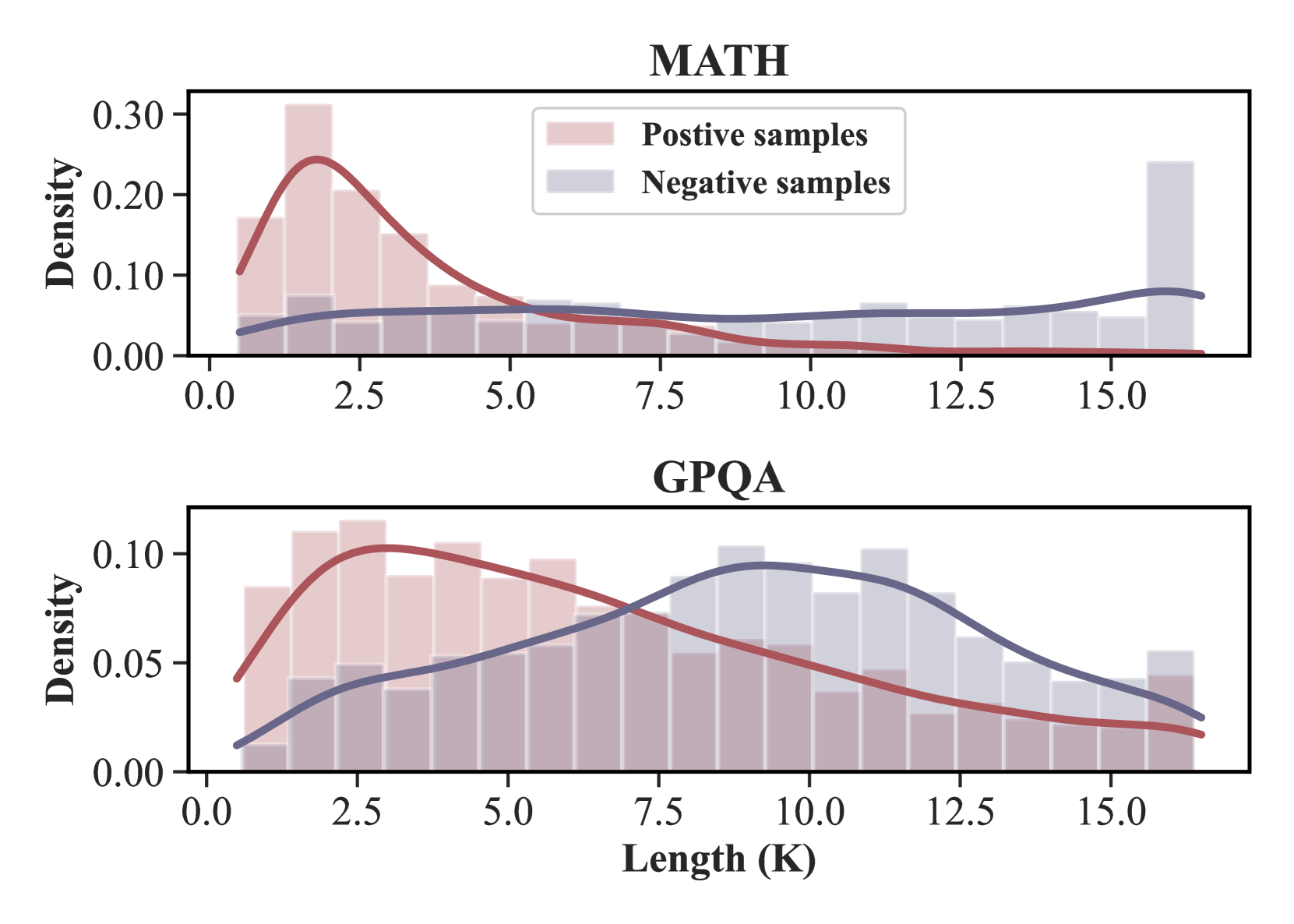
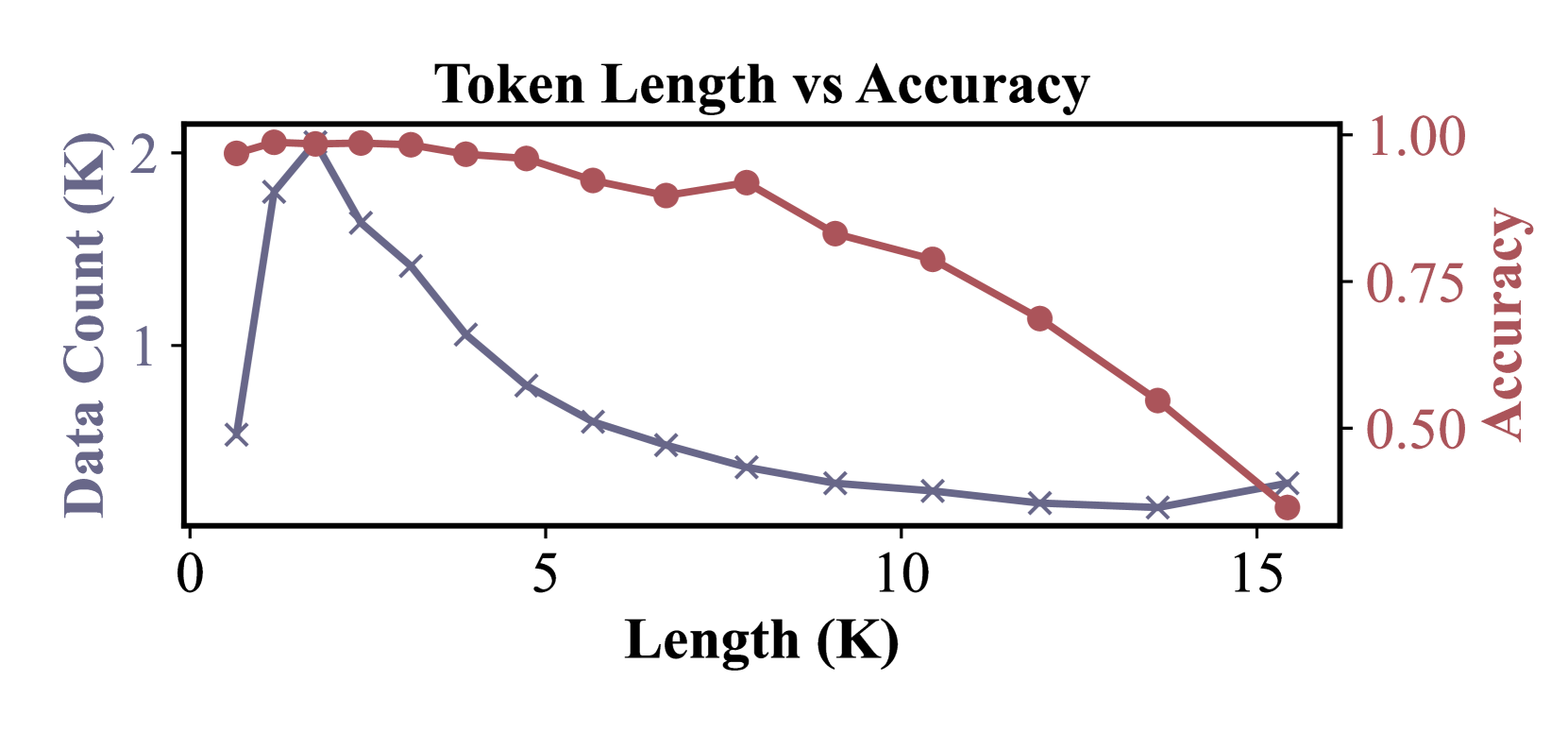
Current heuristics for evaluating Long Chain-of-Thought (LCoT) reasoning, such as token length or step count, fail to accurately predict answer correctness due to the 'overthinking' phenomenon.
Why it matters:
- Models often generate overly long, repetitive chains that degrade performance rather than improve it (overthinking)
- Process Reward Models (PRMs) struggle to scale effectively to the complexity and length of Long CoTs
- Understanding structural failure modes (like over-branching) is essential for diagnosing and improving system-2 reasoning models
Concrete Example:
On MMLU-Pro, DeepSeek-32B's response length is a poor predictor of success (60.0% accuracy), as both correct and incorrect answers often have similar, long token counts due to ineffective looping or repetition.
Key Novelty
LCoT2Tree (Long Chain-of-Thought to Tree)
- Transforms linear text reasoning into a hierarchical tree where nodes are 'thoughts' and edges represent structural transitions (e.g., exploration, backtracking)
- Uses Graph Neural Networks (GNNs) on these extracted trees to predict reasoning success, proving structure is more informative than length
- Identifies specific structural motifs (like 'over-branching') that correlate with reasoning failure
Architecture
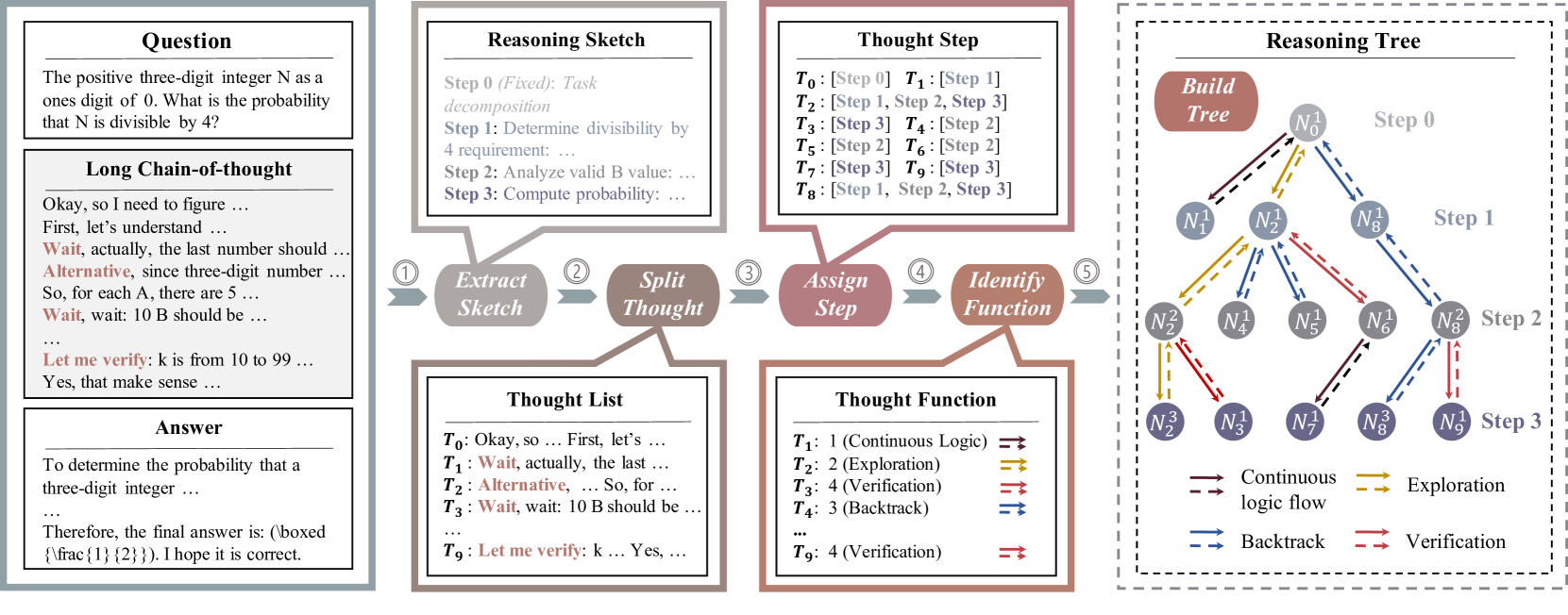
The 5-stage automated pipeline of LCoT2Tree transforming a linear text sequence into a hierarchical tree.
Evaluation Highlights
- Improves binary classification of answer correctness by an average of 5.63% across models compared to length-based baselines
- Achieves +12.46% accuracy improvement over length baselines for DeepSeek-32B on the MMLU-Pro benchmark
- Consistently enhances prediction accuracy across 5 different models, with gains up to +8.27% for Grok-3-mini-beta
Breakthrough Assessment
7/10
Offers a significant methodological shift from analyzing semantic/length features to structural/topological features in reasoning chains, with strong empirical validation across multiple state-of-the-art models.